
(The following is, roughly, the text of a talk I delivered to the IP/IT/Media law discussion group at Edinburgh University on the 25th of November 2016. The text is much longer than what I actually presented and I modified some of the concluding section in light of the comments and feedback I received on the day. I would like to thank all those who were present for their challenging and constructive feedback. All of this builds on a previous post I did on the ‘logical space of algocracy’)
I’m going to talk to you today about ‘algocracy’ - or ‘rule by algorithm’. ‘Algocracy’ is an unorthodox term for an increasingly familiar phenomenon: the use of big data, predictive analytics, machine learning, AI, robotics (etc.) in governance-related systems.
I’ve been thinking and writing about the rise of algocracy for the past three years. I’m currently running a project at NUI Galway about it. The project is kindly funded by the Irish Research Council and will continue until May 2017. I’ve also published a number of articles about the topic, both on my blog and in academic journals. If you are interested in what I have to say, I would like to suggest checking out my blog where I keep an index to all my writings on this topic.
Today I want to try something unusual. Unusual for me at any rate. I’m normally an arguments-guy. In my presentations I like to have an argument to defend. I like to start the presentation by identifying the key premises and conclusions of that argument; I like to clarify the terminology; and I like to spend the bulk of my time defending the argument from a series of attacks.
I’m not going to do that today. I’m going to try something different. I’m going to try to map out a conceptual framework for thinking about the phenomenon of algocracy. I’ll do this in five stages. First, I’ll talk generally about why I think conceptual frameworks of this sort are important and what we should expect from a good conceptual framework. Second, I’ll outline some of the conceptual frameworks that have been offered to date to help us understand algocracies. I’ll explain what I like and don’t like about those frameworks and what I think is missing from the current conversation. Third, I will introduce a method for constructing conceptual frameworks that is based on the work of Christian List. Fourth, I adopt that method and construct my own suggested conceptual framework: the logical space of algocracy. And then fifth, and finally, I will highlight some of the advantages and disadvantages of this logical space.
At the outset, I want to emphasise that everything I present here today is a work in progress. I know speakers always say this in order to protect themselves from criticism, but it’s more true in this case than most. I’ve been mulling over this framework for a couple of years but never pursued it in any great depth. I agreed to give this talk partly in an attempt to motivate myself to think about it some more. Of course, I agreed to this several months ago and, predictably and unsurprisingly, I managed to procrastinate about it until five days ago when I started writing this talk.
I’m not going to say that the ideas presented here are under-baked, but I will say that they are under-cooked. I hope they are thought-provoking and that in the discussion session afterwards we can figure out whether they are worth bringing to the table. (Apologies for the strained culinary metaphor)
1. Why I love Conceptual Frameworks
I use the term ‘conceptual framework’ to describe any thinking tool that tries to unify and cohere concepts and ideas. I’m a big fan of conceptual frameworks. In many ways, I have spent the past half decade collecting them. This is one of the major projects on my blog. I like to review conceptual frameworks developed by other authors, play around with them, see if I truly understand how they work, and then distill them down into one-page images, flowcharts and diagrams.
In preparation for this talk, I decided to look over some of my past work and I thought I would share with you a few of my favourite conceptual frameworks.

First up is Nicole Vincent’s Structured Taxonomy of Responsibility Concepts. This is something I stumbled upon early in my PhD research about the philosophy of criminal responsibility. It has long been noted that the word ‘responsible’ can be used to denote a causal relationship, a moral relationship, a character trait, and an ethical duty, among other things. HLA Hart tried to explain this in his famous parable of the sea captain and the sinking ship. The beauty of Vincent’s framework is that it builds upon the work done by Hart and maps out the inferential relationships between the different concepts of responsibility.

Second, we have Quentin Skinner’s Genealogy of Freedom a wonderfully elegant family tree of the major concepts of freedom that have been articulated and defended since the birth of modern liberalism. Skinner describes the basic core concept of freedom as the power to act plus some additional property. He then traces out three major accounts of that additional property: non-domination; non-interference; and self-realisation.

Third, there is Westen’s four concepts of consent. Consent is often described as being a form of ‘moral magic’ - it is the special ingredient that translates morally impermissible acts (e.g. rape) into permissible ones (e.g. sexual intercourse). But the term consent is used in different ways in legal and moral discourse. Westen’s framework divides these concepts of consent up in two main sub-categories: factual and prescriptive. He then identifies two further sub-types of consent under each category. This helps to make sense of the different claims one hears about consent in moral and legal debates.

Speaking of claims about consent, here’s a slightly different conceptual framework. The previous examples are all taxonomies and organisational systems. Alan Wertheimer’s map of the major moral claims that are made about intoxication and consent to sex is an attempt to work out how arguments relate to one another. Wertheimer starts his detailed paper on the topic by setting out five claims that are typically made about intoxicated consent. My diagram tries to depict the inferential relationships between these claims. I think this helps to give us a ‘lay of the land’ (so to speak) when it comes to this controversial topic. Once we appreciate the lay of the land, we can understand where someone is coming from when they make a claim about intoxicated consent and where they are likely to end up.

Fifth, here is Matthew Scherer’s useful framework for thinking about the regulation of Artificial Intelligence. This adds another dimension to a conceptual framework: a temporal dimension. It shows how different regulatory problems arise from the use of Artificial Intelligence at different points in time. There are ex ante problems that arise as the technology is being created. And there are ex post problems that arise once it has been deployed and used. It is useful to think about the different temporal locations of these problems because some institutions and authorities have more competence to address those problems.

Finally, and another version of the time-sensitive conceptual framework, we have this life-cycle of prescriptive legal theories, developed by David Pozen and Jeremy Kessler. A prescriptive legal theory is a theory of legal decision-making that tries to remove contentious moral content from a decision-making rule (a classic example would be the originalist theory of interpretation). Kessler and Pozen noticed patterns in the development and defence of prescriptive legal theories. Their life-cycle is designed to organise these patterns into distinctive stages. The major insight from this lifecycle is that prescriptive legal theories usually work themselves ‘impure’ - i.e. they end up reincorporating the contentious moral content they were trying to avoid.
I could go on, but I won’t. Like I said, I enjoy collecting and diagramming conceptual frameworks of this sort. But I think it would be more useful at this stage to draw some lessons from these six examples. In particular, it would be useful to highlight the key properties of good conceptual frameworks. I don’t think we can be exhaustive or overly prescriptive in this matter: good, creative scholarship will come up with new and exciting conceptual frameworks. Nevertheless, the following general principles would seem to apply:
A good conceptual framework should enable you to understand some phenomenon of interest.
A good conceptual framework should allow you to see conceptual possibilities you may have missed (e.g. theories of freedom or responsibility that you have overlooked)
A good conceptual framework should enable you to see how concepts relate to one another.
A good conceptual framework should allow you to see opportunities for research and further investigation.
A good conceptual framework should appreciate complexity while aiming for simplicity.
There are also, of course, risks associated with conceptual frameworks. They can be Procrustean. They can become reified (treated as things in themselves rather than as tools for understanding things). They can be overly simplistic, causing us to ignore complexity and miss important opportunities for research. There is a fine line to be walked. Good conceptual frameworks find that line; bad ones miss it.
2. Are there any conceptual frameworks for understanding algocracies?
That’s all by way of set-up. Now we turn to meat of the matter: can we come up with good conceptual frameworks for understanding algocracies? Two things will help us to answer this question. First, getting a better sense of what an algocracy is. Second, taking a look at some of the existing conceptual frameworks for understanding algocracies.
I said at the very start that ‘algocracy’ is an unorthodox term for an increasingly familiar phenomenon: the use of big data, predictive analytics, machine learning, AI, robotics (etc.) in governance-related systems. The term was not coined by me, though I have certainly run with it over the past few years. The term was coined by the sociologist A.Aneesh during his PhD research back in the early 2000s. That research culminated in a book in 2006 called Virtual Migration in which he used the concept to understand changes in the global labour market. He has also used the term in a number of subsequent papers.
Aneesh’s main interest was in different human governance systems. A governance system can be defined, roughly, like this:
Governance system: Any system that structures, constrains, incentivises, nudges, manipulates or encourages different types of human behaviour.
It’s a very general, wishy-washy definition, but ‘governance’ is quite a general wishy-washy term so that seems appropriate. Aneesh drew a contrast between three main types of governance system in his research: markets, bureaucracies and algocracies. A market is a governance system in which prices structure, constrain, incentivise, nudge (etc) human behaviour. And a bureaucracy is a governance system in which rules and regulations structure, constrain, incentivise, nudge (etc.) human behaviour. Which means that an algocracy can be defined as:
Algocracy: A governance system in which computer coded algorithms structure, constrain, incentivise, nudge, manipulate or encourage different types of human behaviour. (Note: the concept is very similar to the ‘code is law’ idea promoted by Lawrence Lessig in legal theory but to explain the similarities and differences would take too long)
In his study of global labour, Aneesh thought it was interesting how more workers in the developing world (particularly India where his studies took place) were working for companies and organisations that were legally situated in other jurisdictions. This was thanks to the new technologies (computers + internet) that facilitated remote work. This gave rise to new algocratic governance systems within corporations, which sidestepped or complemented the traditional market or bureaucratic governance systems within such organisations.
That’s the origin of the term. I tend to use the term in a related but slightly different sense. I certainly look on algocracies as kinds of governance system — ones in which behaviour is shaped by algorithmically programmed architectures. But I also use the term by analogy with terms like ‘democracy’, ‘aristocracy’, ‘technocracy’. In each of those cases, the suffix ‘cracy’ is used to mean ‘rule by’ and the prefix identifies who does the ruling. So ‘democracy’ is ‘rule by the people’ (the demos), aristocracy is ‘rule by aristocrats’ and so on. Algocracy then can also be taken to mean ‘rule by algorithm’, with the emphasis being on rule. In other words, for me ‘algocracy’ captures the authority that is given to algorithmically coded architectures in contemporary life. Whenever you are denied a loan by a credit-scoring algorithm; whenever you are told which way to drive by a GPS routing-algorithm; or whenever your name is added to a no fly list by a predictive algorithm, you are living within an algocratic system. It is my belief, and I think this is borne out in reality, that algocratic systems are becoming more pervasive and important in human life. I especially think is true because algorithms are the common language in which computers, smart devices and robots communicate. So as these artifacts become more pervasive, so too will the phenomenon of algocracy.
So what kinds of conceptual frameworks can we bring to bear on this phenomenon? Some work has been done already on this score. There are emerging bodies of scholarship in law, sociology, geography, philosophy, and information systems theory (among many more) that address themselves to the rise of algocracy (though they tend not to use that term) and some scholars within those fields have developed organisational frameworks for understanding and researching algocracies. I’ll focus on legal contributions in this presentation since that’s what I am most familiar with, and since I think what has been presented in legal theory so far tends to be shared by other disciplines.
I’ll start by looking at two frameworks that have been developed in order to help us understand how algocratic systems work.
The first tries to think about various stages involved in the construction and implementation of algocratic system. Algocracies do things. They make decisions about human life; they set incentives; they structure possible forms of behaviour; and so on. How do they manage this? Much of the answer lies how they use data. Zarsky (2013) suggests that there are three main stages in an algocratic system: (i) a data collection stage (where information about the world and relevant human beings is collected and fed into the system); (ii) a data analysis stage (where algorithms structure, process and organise that data into useful or salient chunks of information) and (iii) a data usage stage (where the algorithms make recommendations or decisions based on the information they have processed).
Citron and Pasquale (2014) develop a similar framework. They use different terminology but they talk about the same thing. They focus in particular on credit-scoring algocratic systems which they suggest have four main stages to them. This is illustrated in the diagram below:

Effectively, what they have done is to break Zarsky’s ‘usage’ stage into two: a dissemination stage (where the information processed and analysed by the algorithms gets communicated to a decision-maker) and a decision-making stage (where the decision-maker uses the information to do something concrete to an affected party, e.g. deny them a loan because of a bad credit score).
Another thing that people have tried to do is to figure out how humans relate to or get incorporated into algocratic systems. A common classificatory framework — which appears to have originated in the literature on automation — distinguishes between three kinds of system:
Human-in-the-loop System: These are algocractic systems in which an input from a human decision-maker is necessary in order for the system to work, e.g. to programme the algorithm or to determine what the effects of the algorithmic recommendation will be.
Human-on-the-loop Systems These are algocratic systems which have a human overseer or reviewer. For example, an online mortgage application system might generate a verdict of “accept” or “reject” which can then be reviewed or overturned by a human decision-maker. The system can technically work without human input, but can be overridden by the human decision-maker.
Human-out-of-the-loop Systems This is a fully algocratic system, one which has no human input or oversight. It can collect data, generate scores, and implement decisions without any human input.
This framework is useful because relationship of humans to the systems is quite important when we turn to consider the normative and ethical implications of algocracy.
This brings us to the third type of conceptual framework I wanted to mention. These ones focus on identifying and taxonomising the various problems that arise from the emergence of algocratic systems. Zarsky, for instance, developed the following taxonomy, which focused on two main types of normative problem: fairness-related problems and efficiency-related problems. I constructed this diagram to visually represent Zarsky’s taxonomy.

More recently, Mittelstadt et al have proposed a six-part conceptual map to help understand the ethical challenges posed by algocratic decision-making systems. This can be found in their paper ‘The Ethics of Algorithms’.
While each of these conceptual frameworks has some use, I find myself dissatisfied by the work that has been done to date. First, I worry that the frameworks introduced to help us understand how algocratic systems work are both too simplistic and too disconnected. It is important to think about the different stages inside an algocratic system and about how humans relate to and get affected by those systems. But it is important to remember that the relations that humans have to these systems can vary, depending on the stage that we happen to be interested in. There is a degree of complexity to how these stages get constructed and this is something that is missed by the simple ‘in the loop/on the loop/out of the loop’ framework. Furthermore, while I’m generally much happier with the work done on taxonomising and categorising the ethical challenges of algocracy, I worry that this work also tends to be disconnected from the complexities of algocratic systems. This is something that a good conceptual framework would avoid.
So can we come up with one?
3. A Model for Building Conceptual Frameworks: List’s Logical Spaces
I think we can. And I think some of the work done by Christian List is instructive in this regard. So what I propose to do in the remainder of this talk is develop a conceptual framework for understanding algocracy that is modelled on a series of conceptual frameworks developed by List.
List, in case you don’t know him, is a philosopher at the London School of Economics. He is a major proponent of formalised and axiomatised approaches to philosophy. Most of his early work is on public choice theory, voting theory and decision theory. More recently, he has turned his attention to other philosophical debates (e.g. philosophy of mind and free will). He has also written a couple of papers in the past half decade on the logical spaces in which different political concepts such a ‘democracy’ and ‘freedom’ live.
List’s logical spaces try to identify all the concepts of freedom or democracy that are possible, given certain constraints. It is difficult to understand this methodology in the abstract so let’s look at his logical space of freedom and democracy for guidance.
Freedom is a central concept in liberal political theory. Indeed, liberalism is, in essence, founded on the notion that political systems must respect individual freedom. But what does this freedom consist in? List argues that two major theories of freedom predominate in contemporary debates (cf. Skinner’s genealogy of freedom, which I detailed earlier on): freedom as non-interference and freedom as non-domination. The former holds that we are free if we are free from relevant external constraints; the latter holds that we are free if we are robustly free from non-arbitrary constraints.
The difference is subtle to the uninitiated but essential to those who care about these things. I have written several posts about both theories in the past if you care to learn more (LINKs). List suggests that the theories vary along two dimensions: the modal and the moral. That is to say, they vary depending on (a) whether they think the freedom to act requires not just freedom in this actual world but freedom across a range of possible worlds; and (b) whether they only recognise as interferences with freedom those interferences that are not morally grounded (i.e. interferences that are ‘arbitrary’). Freedom as non-interference is, typically, non-modal and non-moral: it focuses on what happens in the actual world, but counts all relevant interferences in the actual world, regardless of their moral justification, as freedom-undermining. Contrast that with republican theories of freedom as non-domination. These theories are modal and moral: they depend on the absence of interference across multiple possible worlds but only count interferences that are non-arbitrary. (Technical aside: some republicans, like Pettit, have argued that freedom as non-domination can be de-moralised but List argues that this is an unstable position - I won’t get into the details here)
What’s interesting from List’s perspective is that even though most of the contemporary debate settles around these two concepts of freedom, there is a broader logical space of freedom that is being ignored. After all, there are two dimensions along which theories of freedom can vary which suggests, at a minimum, four logically possible theories of freedom. The two-by-two matrix below depicts this logical space:
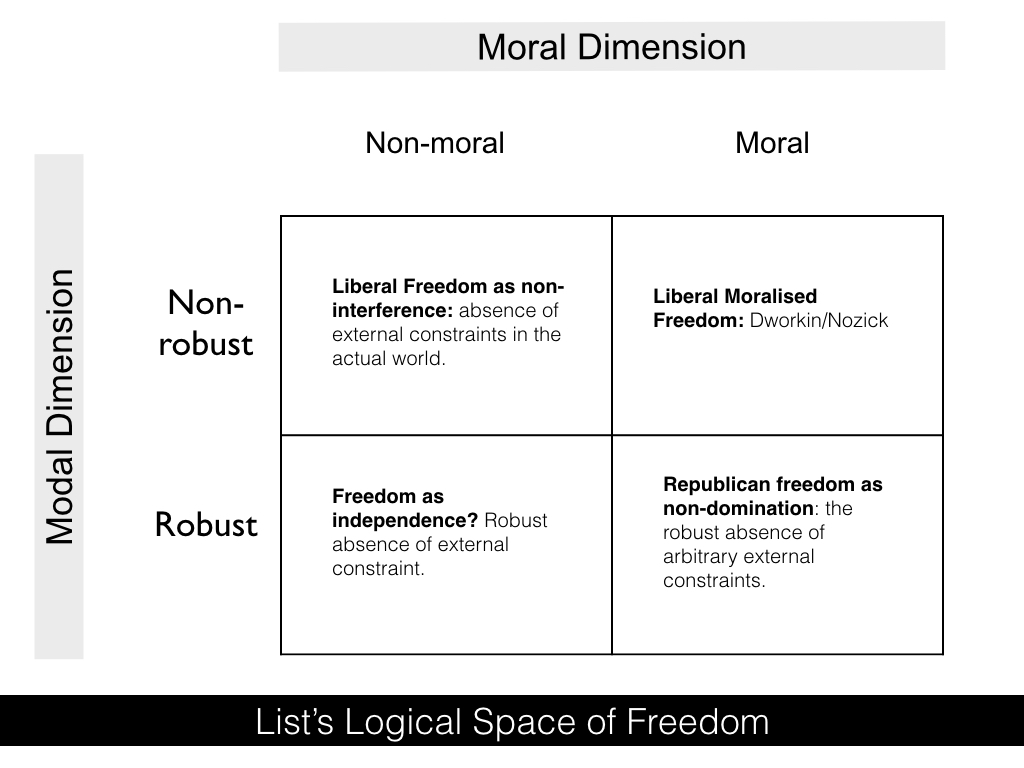
The advantages of mapping out this logical space become immediately apparent. They allow List to discover and argue in favour of an ignored or overlooked theory of freedom: the one in the bottom right corner. And this is exactly what he does in a paper published last year in Ethics with Laura Valentini entitled ‘Freedom as Independence’.
How about democracy? List takes a similar approach. He argues that democracy is, at its root, a collective decision-making procedure. It is a way of taking individual attitudes toward propositions or claims (e.g. ‘I prefer candidate A to candidate B’ or ‘I prefer policy X to policy Y’) and aggregating them together to form some collective output. This is illustrated schematically in the diagram below.

One of List’s key arguments, developed in his paper ‘The Logical Space of Democracy’ is that the space of logically possible collective decision procedures — i.e. ways of going from the individual attitudes to collective outputs — is vast. Much larger than any human can really comprehend. To give you a sense of how vast it is, imagine a really simple decision problem in which two people have to vote on two options: A and B. There are four possible combinations of votes (as each voter has two options). And there are several possible ways to go from those combinations to a collective decision (well 24 to be precise). For example, you could adopt a constant A procedure, in which the collective attitude is always A, irrespective of the individual attitudes. Or you could have a constant B procedure, in which the collective attitude is always B, irrespective of the individual attitudes. We would typically exclude such possibilities because they seem undesirable or counterintuitive, but they do lie within the space of logically possible aggregation functions. Likewise, there are dictatorial decision procedures (always go with voter 1, or always go with voter 2) and inverse dictatorial decision procedures (always do the opposite of voter 1, or the opposite of voter 2).
You might find this slightly silly because, at the end of the day, there are still only two possible collective outputs (A or B). But it is important to realise that there are many logically possible ways to go from the individual attitudes to the collective one. This highlights some of the problems that arise when constructing collective decision procedures. And, remember, this is just a really simple example involving two voters and two options. The logical space gets unimaginably large if we go to decision problems involving, say, ten voters and two options (List has the calculation in his paper, it is 21024).
A logical space with that many possibilities would not provide a useful conceptual framework. Fortunately, there is a way to narrow things down. List does this by adopting an axiomatic method. He specifies some conditions (axioms) that any democratic decision procedure ought to satisfy in advance, and then limits his search of the logical space of possible decision procedures to the procedures that satisfy these conditions. In the case of democratic decision procedures, he highlights three conditions that ought to be satisfied: (i) robustness to pluralism (i.e. the procedure should accept any possible combination of individual attitudes); (ii) basic majoritarianism (i.e. the collective decision should reflect the majority opinion); and (iii) collective rationality (i.e. the collective output should meet the basic criteria for rational decision making). He then highlights a problem with these three conditions. It turns out that it is impossible to satisfy all three of them at the same time (due to classic ‘voting paradoxes’). Consequently, the space of logically possible democratic decision procedures is smaller than we might first suppose. We are left with only those decision procedures that satisfy at least two of the mentioned conditions. Once you pare the space of possibilities down to this more manageable size you can start to think more seriously about its topographical highlights. That’s what the diagram below tries to illustrate.

I don’t want to dwell on the intricacies of List’s logical spaces, I’m only referencing them because I think they provide a useful methodology for constructing conceptual frameworks. They balance the tradeoff between complexity and simplicity quite effectively and exhibit a number of other features listed earlier on. By considering the various dimensions along which particular phenomena can vary, List allows us to see conceptual possibilities that are often overlooked. Sometimes the number of conceptual possibilities identified can be overwhelming, but by applying certain axioms we can constrain our search of the logical space and make it more manageable.
4. Constructing A Logical Space of Algocracy
So can we apply the same approach to algocracy? I think we can. We can start by identifying the parameters (dimensions) along which various algocractic procedures vary.
At a first pass, three parameters seem to define the space of possible algocratic decision procedures. The first is the particular domain or type of decision-making. Legal and bureaucratic agencies make decisions across many different domains. Planning agencies make decisions about what should be built and where; revenue agencies sort, file and search through tax returns and other financial records; financial regulators make decisions concerning the prudential governance of financial institutions; energy regulators set prices in the energy industry and enforce standards amongst energy suppliers; the list goes on and on. In the formal model I outline below, the domain of decision-making is ignored. I focus instead on two other parameters defining the space of algocratic procedures. But this is not because the domain is unimportant. When figuring out the strengths or weaknesses of any particular algocratic decision-making procedure, the domain of decision-making should always be specified in advance.
The second parameter concerns the main components of the decision-making ‘loop’ that is utilised by these agencies. In section two, I mentioned Zarsky, Citron and Pasquale’s attempts to identify the different ‘stages’ in algocratic decision-procedures. One thing that strikes me about the stages identified by these authors is how closely they correspond to the stages identified by authors looking at automation and artificial intelligence. For instance, the collection, processing and usage stages identified by Zarsky et al feel very similar to the sensing, processing and actuating stages identified by AI theorists and information systems engineers.
This makes sense. Humans in legal-bureaucratic agencies use their intelligence when making decisions.Standard models of intelligence divide this capacity into three or four distinct tasks. If algocratic technologies are intended to replace or complement that human intelligence, it would make sense for those technologies to fit into those distinct task stages.
My own preferred model for thinking about the stages in a decision-making procedure is to break it down into four distinct stages. As follows:
(a) Sensing: the system collects data from the external world.
(b) Processing: the system organises that data into useful chunks or patterns and combines it with action plans or goals.
(c) Acting: the system implements its action plans.
(d) Learning: the system uses some mechanism that allows it to learn from what it has done and adjust its earlier stages (this results in a ‘feedback loop’).
Although individual humans within bureaucratic agencies have the capacity to perform these four tasks themselves, the work of an entire agency can also be conceptualised in terms of these four tasks. For example, a revenue collection agency will take in personal information from the citizens in a particular state or country (sensing). These will typically take the form of tax returns, but may also include other personal financial information. The agency will then sort that collected information into useful patterns, usually by singling out the returns that call for greater scrutiny or auditing (processing). Once they have done this they will actually carry out audits on particular individuals, and reach some conclusion about whether the individual owes more tax or deserves some penalty (acting). Once the entire process is complete, they will try to learn from their mistakes and triumphs and improve the decision-making process for the coming years (learning).
The important point in terms of mapping out the logical space of algocracy is that algorithmically coded architectures could be introduced to perform one or all of these four tasks. Thus, there are subtle and important qualitative differences between the different types of algocratic system, depending on how much of the decision-making process is taken over by the computer.
In fact, it is more complicated than that and this is what brings us to the third parameter. This one concerns the precise relationship between humans and algorithms for each task in the decision-making loop. As I see it, there are four general relationship-types that could arise: (1) humans could perform the task entirely by themselves; (2) humans could share the task with an algorithm (e.g. humans and computers could perform different parts of the analysis of tax returns); (3) humans could supervise an algorithmic system (e.g. a computer could analyse all the tax returns and identify anomalies and then a human could approve or disapprove their analysis); and (4) the task could be fully automated, i.e. completely under the control of the algorithm.
This is where things get interesting. Using the last two parameters, we can construct a grid which we can use to classify algocratic decision-procedures. The grid looks something like this:

This grid tells us that when constructing or thinking about an algocratic system we should focus on the four different tasks in the typical intelligent decision-making loop and ask of each task: how is this task being distributed between the humans and algorithms? When we do so, we see the logical space of possible algocratic decision procedures.
5. Advantages and Disadvantages of the Logical Space Model
That brings us to the critical question: does this conceptual framework have any of the virtues I mentioned earlier on?
I think it has a few. I think it captures the complexity of algocracy in a way that existing conceptual frameworks do not. It tell us that there is a large logical space of possible algocratic systems. Indeed, it allows us to put some numbers on it. Since there are four stages and four possible relationship-types between humans and computers at those four stages, it follows that there are 4
But the interpretability/non-interpretability distinction is just one among many possible candidates for a third dimension of variance. Which one we pick will depend on what we are interested in (I’ll return to this point below).
Another virtue of the logical space model is that it gives us an easy tool for coding the different possible types of algocratic system. For the two-dimensional model, I suggest that this be done using square brackets and numbers. Within the square brackets there would be four separate number locations. Each location would represent one of the four decision-making tasks. From left-to-right this would read: [sensing; processing; acting; learning]. You then replace the names of those tasks with numbers ranging from 1 to 4. These numbers would represent the way in which the task is distributed between the humans and algorithms. The numbers would correspond to the numbers given previously when explaining the four possible relationships between humans and algorithms. So, for example:
[1, 1, 1, 1] = Would represent a non-algocratic decision procedure, i.e. one in which all the decision-making tasks are performed by humans.
[2, 2, 2, 2] = Would represent an algocratic decision procedure in which each task is shared between humans and algorithms.
[3, 3, 3, 3] = Would represent an algocratic decision procedure in which each task is performed entirely by algorithms, but these algorithms are supervised by humans with some residual possibility of intervention.
[4, 4, 4, 4] = Would represent an pure algocratic decision procedure in which each task is performed by an algorithm, with no human oversight or intervention.
If we created a three dimensional logical space, we could simply modify the coding system by adding a letter after each number to indicate the additional variance. For example, if we adopted the interpretability/non-interpretability dimension, we could add ‘i’ or ‘ni’ after each number to indicate whether the step in the process was interpretable (i) or not (ni). As follows:
[4i, 4i, 4i, 4i] = Would represent a pure algocratic procedure that is completely interpretable
[4i, 4ni, 4i, 4ni] = Would represent a pure algocratic procedure that is interpretable at the sensing and acting stages, but not at the processing and learning stages.
This coding mechanism could have some practical advantages. Three are worth mentioning. First, it could give any designer and creator of an algocratic system a quick tool for figuring out what kind of system they are creating and the potential challenges that might be raised by the construction of that system. Second, it could give a researcher something to use when investigating real-world algocratic systems and seeing whether they share further properties. For instance, you could start investigating all the [3, 3, 3, 3] systems across various domains of decision-making and see whether the human supervision is active or passive across those domains. Third, it might give us a simple tool for measuring how algocratic a system is or how algocratic it becomes over time. So we might be able to say that a [4ni, 4ni, 4ni, 4ni] is more algocratic than a [4i, 4i, 4i, 4i] and we might be able to spot the drift towards more algocracy within a decision-making domain.
But there are also clearly disadvantages with the logical space model. The most obvious is that the four stages and four relationships are not discrete in the way that the model presumes. To say that a task is ‘shared’ between a human and an algorithm is to say something imprecise and vague. There may be many different possible ways in which to share a task. Not all of them will be the same. This also true for the description of the tasks. ‘Processing’, ‘collecting’ and ‘learning’ are all complicated real-world tasks. There are many different ways to process, collect and learn. That additional complexity is missed by the logical space model.
It’s hard to say whether this a fatal objection or not. All conceptual models involve some abstraction and simplification of reality. And all conceptual models ignore some element of variation. List’s logical space of freedom, for instance, involves similarly large amounts of abstraction and simplification. To say that theories of freedom vary along modal and moral dimensions is to say something very vague and imprecise. Specific theories of freedom will vary in how modal they are (i.e. how many possible worlds they demand the absence of interference in) and in their understanding of what counts as a morally legitimate interference. As a result of this, List prefers to view his logical space of freedom as a ‘definitional schema’ - something that is fleshed out in more detail with specific conceptualisations of the four main categories of freedom. It is tempting to view the logical space of algocracy in a similar light.
Another obvious problem with the logical space model is that it is constructed with a particular set of normative challenges in mind. I was silent about this in my initial description of it, and indeed I didn’t fully appreciate it until I afterwards, but it’s pretty clear looking back on it that my logical space is useful primarily for those with an interest in the procedural virtues of an algocratic system. As I have argued elsewhere, one of the main problems with the rise of algocracy is that it could undermine meaningful human participation in and comprehension of the systems that govern our lives. That’s probably why my logical space model puts such an emphasis on the way in which tasks are shared between humans and algorithms. I’m concerned that when there is less sharing, there is less participation and comprehension.
But this means that the model is relatively silent about some of the other normative concerns one could have about these technologies (e.g. bad data, biased data, negative consequences). It’s not that these concerns are completely shut out or shut down; it’s just that they aren’t going to be highlighted simply by identifying the location with the logical space that is occupied by any particular algocratic system. What could happen, however, is that empirical investigation of algocratic systems with similar codes could reveal additional shared normative advantages/disadvantages, so that the code becomes shorthand for those other concerns.
Again, it’s hard to say whether this is fatal or not. It might just mean that the logical space I constructed is not ‘the’ logical space of algocracy but rather ‘a’ logical space of algocracy. Other people, with other interests, could construct other logical spaces. That’s doesn’t mean this particular logical space is irrelevant or useless; it just means its relevance and utility is more constrained.
Anyway, I think I have said enough for now. I’ll leave things there and hand it over to you for questions.
No comments:
Post a Comment