The claim that AI systems are biased is common. Perhaps the classic example is the COMPAS algorithm used to predict recidivism risk amongst prisoners. According to a widely-discussed study published in 2016, this algorithm was biased against black prisoners, giving them more false positive ‘high risk’ scores, than white prisoners. And this is just one example of a biased system. There are many more that could be mentioned, from facial recognition systems that do a poor job recognising people with darker skin tones, to employment algorithms that seem to favour male candidates over female ones.
But what does it mean to say that AI or algorithmic system is biased? Unfortunately, there is some disagreement and confusion about this in the literature. People use the term ‘bias’ to mean different things. Most notably, some people use it in a value-neutral, non-moralised sense whereas others use it in a morally-loaded pejorative sense. This can lead to a lot of talking at cross purposes. But also some people use the term to describe different types or sources of bias. A lot would be gained if we could disambiguate these different types.
So that’s what I will try to do in the remainder of this article. I will start by distinguishing between moral and non-moralised definitions of ‘bias’. I will then discuss three distinct causes of bias in AI systems, as well as how bias can arise at different stages in the developmental pipeline for AI systems. Nothing I say here is particularly original. I draw heavily from the conceptual clarifications already provided by others. All I hope is that I can cover this important topic in a succinct and clear way.
1. Moralised and Non-Moralised Forms of Bias
One of the biggest sources of confusion in the debate about algorithmic bias is the fact that people use the term ‘bias’ in moralised and non-moralised ways. You will, for example, hear people say that algorithms are ‘inherently biased’ and that ‘we want them to be biased’. This is true, in a sense, but then creates problems when people start to criticise the phenomenon of algorithmic bias in no uncertain terms. To avoid this confusion, it is crucial to distinguish between the moralised and non-moralised senses of ‘bias’.
Let’s start with the non-moralised sense. All algorithms are designed with a purpose in mind. Google’s pagerank algorithm is intended to sort webpages into a ranking that respects their usefulness or relevance to a search user. Similarly, the route-planning algorithm on Google Maps (or similar mapping services) tries to select the quickest and most convenient route between A and B. In each case, there is a set of possible outcomes among which the algorithm can select, but it favours a particular subset of outcomes because those match better with some goal or value (usefulness, speed etc).
In this sense it is true to say that most, if not all, algorithms are inherently biased. They are designed to be. They are designed to produce useful outputs and this requires that they select carefully from a set of possible outputs. This means they must be biased in favour of certain outcomes. But there is nothing necessarily morally problematic about this inherent bias. Indeed, in some cases it is morally desirable (though this depends on the purpose of the algorithm). When people talk about algorithms being biased in this sense (of favouring certain outputs over others), they are referring to bias in the non-moralised or neutral sense.
How does this contrast with the moralised sense of ‘bias’? Well, although all algorithms favour certain kinds of output, sometimes they will systematically favour outputs that have an unfair impact on a certain people or populations. A hiring algorithm that systematically favours male over female candidates would be an example of this. It reflects and reproduces gender-based inequality. If people refer to such a system as being ‘biased’ they are using the term in a moralised sense: to criticise its moral impact and, perhaps, to blame and shame those that created it. They are saying that this is a morally problematic algorithm and we need to do something about it.
There appear to two conditions that must be met in order for an algorithm to count as biased in this second, moralised, sense:
Systematic output: The algorithm must systematically (consistently and predictably) favour one population/group over another, even if it this effect is only indirect.
Unfair effect: The net effect of the algorithm must be to treat populations/groups differently for morally arbitrary or illegitimate reasons
These conditions are relatively straightforward but some clarifications may be in order. The systematicity condition is there in order to rule out algorithms that might be biased, on occasions, for purely accidental reasons, but not on a repeated basis. Furthermore, when I say that the systematic effect on one population may be ‘indirect’ what I mean is that the algorithm itself may not be overtly or obviously biased against a certain population, but nevertheless affects them disproportionately. For example, a hiring algorithm that focused on years spent in formal education might seem perfectly legitimate on its face, with no obvious bias against certain populations, but its practical effect might be rather different. It could be that certain ethnic minorities spend less time in formal education (for a variety of reasons) and hence the hiring algorithm disproportionately disfavours them.
The unfairness condition is crucial but tricky. As noted, some forms of favourable or unfavourable treatment might be morally justified. A recidivism risk score that accurately identifies those at a higher risk of repeat offending would treat a sub-population of prisoners unfavourably, but this could be morally justified. Other forms of unfavourable treatment don’t seem justified, hence the furore about the recidivism risk score that treats black prisoners differently from white prisoners. These are relatively uncontroversial cases. The problem is that there are sometimes grounds for reasonable disagreement as to whether a certain forms of favourable treatment are morally justified or not. This moral disagreement will always affect debates about algorithmic bias. This is unavoidable and, in some cases, can be welcomed: we need to be flexible in understanding the boundaries of our moral concepts in order to allow for moral progress and reform. Nevertheless, it is worth being aware of it whenever you enter a conversation about algorithmic bias. We might not always agree whether a certain algorithm is biased in the moralised sense.
One last point before we move on. In the moralised sense, a biased algorithm is harmful. It breaches a moral norm, results in unfair treatment, and possibly violates rights. But there are many forms of morally harmful AI that would not count as biased in the relevant sense. For instance, an algorithmic system for piloting an airplane might result in crashes in certain weather conditions (perhaps in a systematic way), but this would not count as a biased algorithm. Why not? Because, presumably, the crashes would affect all populations (passengers) equally. It is only when there is some unfair treatment of populations/groups that there is bias in the moralised sense.
In other words, it is important that the term ‘bias’ does not do too much heavy-lifting in debates about the ethics of AI.
2. Three Causes of Algorithmic Bias
How exactly does bias arise in algorithmic systems? Before I answer that allow me to indulge in a brief divagation.
One of the interesting things that you learn when writing about the ethics of technology is how little of it is new. Many of the basic categories and terms of debate have been set in stone for some time. This is true for much of philosophy of course, but those of use working in ‘cutting edge’ areas such as the ethics of AI sometimes like to kid ourselves that we are doing truly innovative and original work in applied ethics. This is rarely the case.
This point was struck home to me when I read Batya Friedman and Helen Nissenbaum’s paper ‘Bias in Computer Systems’. The paper was published in 1996 — a lifetime ago in technology terms — and yet it is still remarkably relevant. In it, they argue that there are three distinct causes of bias in ‘computer systems’ (a term which can covers algorithmic and AI systems too). They are:
Preexisting bias: The computer system takes on a bias that already exists in society or social institutions, or in the attitudes, beliefs and practices of the people creating it. This can be for explicit, conscious reasons or due to the operation of more implicit factors.
Technical bias: The computer system is technically constrained in some way and this results in some biased output or effect. This can arise from hardware constraints (e.g. the way in which algorithmic recommendations have to be displayed to human users on screens with limited space) or problems in software design (e.g. how you translate fuzzy human values and goals into precise quantifiable targets).
Emergent bias: Once the system is deployed, something happens that gives rise to a biased effect, either because of new knowledge or changed context of use (e.g. a system used in a culture with a very different set of values).
Friedman and Nissenbaum give several examples of such biases in action. They discuss, for example, an airline ticket booking system that was used by US travel agents in the 1980s. The system was found to be biased in favour of US airlines because it preferred connecting flights from the same carrier. On the face of it, this wasn’t an obviously problematic preference (since there was some convenience from the passenger’s perspective) but in practice it was biased because few non-US airlines offered internal US flights. Similarly, because of how the flights were displayed on screen, travel agents would almost always favour flights displayed on the first page of results (a common bias among human users). These would both be examples of technical bias (physical constraints and design choices).
3. The Bias Pipeline
Friedman and Nissenbaum’s framework is certainly still useful, but we might worry that it is a little crude. For example, their category of ‘preexisting bias’ seems to cover a wide range of different underlying causes of bias. Can we do better? Is there a more precise way to think about the causes of bias?
One possibility is the framework offered by Sina Fazelpour and David Danks in their article ‘Algorithmic Bias: Senses, Sources, Solutions’. This is a more recent entry into the literature, published in 2021, and focuses in particular on the problems that might arise from the construction and deployment of machine learning algorithms. This makes sense since a lot of the attention has shifted away from ‘computer systems’ to ‘machine learning’ and ‘AI’ (though, to be clear, I’m not sure how much of this is justified).
Fazelpour and Danks suggest that instead of thinking about general causal categories, we think instead about the process of developing, designing and deploying an algorithmic system. They call this the ‘pipeline’. It starts with the decision to use an algorithmic system to assist (or replace) a human decision-maker. At this stage you have to specify the problem that you want the system to solve. Once that is done, you have to design the system, translating the abstract human values and goals into a precise and quantifiable machine language. This phase is typically divided into two separate processes: (i) data collection and processing and (ii) modelling and validation. Then, finally, you have to deploy the system in the real world, where it starts to interact with human users and institutions.
Bias can arise at each stage in the process. To make their analytical framework more concrete they use a case study to illustrate the possible forms of bias: the construction of a ‘student success’ algorithm for use in higher education. The algorithm uses data from past students to predict the likely success of future students on various programs. Consider all the ways in which bias could enter into the pipeline for such an algorithm:
Problem specification: You have to decide what counts as ‘student success’ — i.e. what is it that you are trying to predict. If you focus on grades in the first year of a programme, you might find that this is biased against first generation students or students from minority backgrounds who might have a harder time adjusting to the demands of higher education (but might do well once they have settled down). You also face the problem that any precise quantifiable target for student success is likely to be an imperfect proxy measure for the variable you really care about. Picking one such target is likely to have unanticipated effects that may systematically disadvantage one population.
Data collection: The dataset which you rely on to train and validate your model might be biased in various ways. If the majority of previous students came from a certain ethnic group, or social class, your model is unlikely to be a good fit for those outstide of those groups. In other words, if there is some preexisting bias built into the dataset, this is likely to be reflected in the resultant algorithm. This is possibly the most widely discussed cause of algorithmic bias as it stems from the classic: ‘garbage in, garbage out’ problem.
Modelling and Validation: When you test and validate your algorithm you have to choose some performance criterion against which to validate it, i.e. something that you are going to optimise or minimise. For example, you might want to maximise predictive success (how many students are accurately predicted to go on to do well) or minimise false positive/negative errors (how many students are falsely predicted to do well/badly). The choice of performance criterion can result in a biased outcome. Indeed, this problem is that the heart of the infamous debate about the COMPAS algorithm that I mentioned at the start of this article: the designers tried to optimise predictive success and this resulted in the disparity in false positive errors.
Deployment: Once the algorithm is deployed there could be some misalignment between the user’s values and those embodied in the algorithm, or they could use it in an unexpected way, or in a context that is not a good match for the algorithm. This can result in biased outcomes. For example, imagine using an algorithm that was designed and validated in a small, elite liberal arts college in the US, in a large public university in Europe (or China). Or imagine that the algorithmic prediction is used in combination with other factors by a human decision-making committee. It is quite possible that the humans will rely more heavily on the algorithm when it confirms their pre-existing biases and will ignore it when it does not.
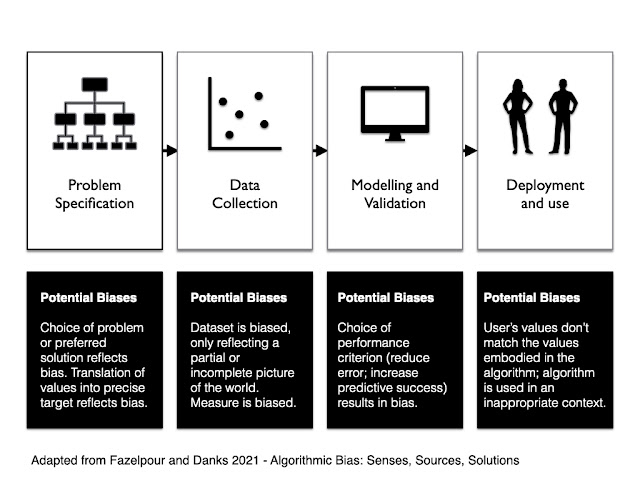
These are just some examples. Many more could be given. The important point, drawn from both Friedman and Nissenbaum’s framework, and the one suggested by Fazelpour and Danks, is that there can be many different (and compounding) causes of bias in algorithmic systems. It is important to be sensitive to these different causes if we want to craft effective solutions. For instance, a lot of energy has been expended in recent times on developing technical solutions to the problem of bias. These are valuable, but not always. They may not be targeted at the right cause. If the problem comes from how the algorithm is used by humans, in a particular decision-making context, then all the technical wizardry may be for naught.
_%E2%80%93_Tin_Wind_Up_%E2%80%93_Tiny_Zoomer_Robots_%E2%80%93_Front.jpg)


