It's time to do the usual end of year review of my academic publications. I've noticed quite a number of my colleagues complaining about this practice on Twitter, suggesting that people who do such retrospective lists are engaging in a painfully self-aggrandising form of productivity signalling. These colleagues argue for greater modesty and self-deprecation in such annual reviews, and argue that we should celebrate non-work related 'achievements' as well.
I sympathise, but as I explained in one of the many outputs from my super-productive year, both of these attitudes are symptomatic of an underlying malaise in our work culture. So I offer this list unapologetically.
As per my rules from last year, I've only included items that were published for the first time in 2018. I've excluded journal articles that were previously published in an online only version and got bumped into an official journal issue this year. I've also excluded items that were accepted for publication in 2018 but haven't yet seen the light of day.
This year has been a relatively quiet one on the blogging front. Life has gotten in the way. Still, I did manage to post some decent pieces. Here are 12 of my favourites -- one from each month. I didn't use any objective metric to decide on what to include. I just focused on the ones I happened to like when looking back over them this morning. That said, with only two exceptions, my choices coincide with the 'most read' post from each month.
Popper's Critique of Utopianism and Defence of Negative Utilitarianism (Jan 2018) - I've been thinking a lot about utopianism in the past year or so. This is largely as a result of a book project I'm working on. This post, from January, is my critique of Karl Popper's critique of utopian political philosophies.
Taking the Relational Turn: How should we think about the moral status of robots, animals and others? (Feb 2018) - David Gunkel kindly invited me to take part in a workshop about his book Robot Rights at the Robophilosophy Conference in February of this year. This post was part of my preparation for this workshop. It analyses Gunkel and Coeckelbergh's critique of traditional approaches to the ascription of moral status and their defence of something they call the 'Relational turn'.
Should we care about inequality? A critical analysis of Pinker's optimism (Mar 2018) - Steven Pinker made quite a splash with his book Enlightenment Now earlier in the year. While I agree with a lot of what he has to say, and I think some of the criticism of his book is misguided, I did take issue with some of the things he said in his chapter on inequality.
Running to Stay Still: The Vice of Delayed Gratification (April 2018) - We're often told that delaying gratification is the path to success, but what if we're wrong? What if it is the path to perpetual dissatisfaction? That's the argument considered in this post.
Algorithmic Micro-Domination: Living with the Threat of Algocracy (June 2018) - This post was a return to some of the more traditional themes of this blog. It uses the republican theory of freedom as non-domination to analyse algorithmic governance technologies.
Transhumanism as Utopianism: A Critical Analysis (July 2018) - Continuing the obsession with utopianism, this post considers whether transhumanism can be considered a utopianist movement. I argue that it can, and that this is not a major problem.
The Optimist's Guide to Schopenhauer's Pessimism (Sep 2018) - Given my general mood for the past 12 months, it was perhaps unsurprising that I spent the month of September brooding over the merits of having an optimistic or pessimistic outlook on life. In this post, I assessed Schopenhauer's famous case for pessimism.
The Automation of Policing: Challenges and Opportunities (Oct 2018) - Automating technologies already play a significant role in modern policing, but what does the future hold? Can we expect more automation of key policing functions? Will this move us away from a 'detect and enforce' model of policing to a 'predict and prevent' model? I offer my thoughts on these, and other, questions in this post.
Am I a Hypocrite? A Philosophical Self-Assessment (Nov 2018) - We're all a little bit hypocritical from time to time. Is this a serious moral failing (as many philosophers argue) or is it a weakness that should engender sympathy? I make the case for a nuanced and less moralistic understanding of hypocrisy, using my own behaviour as a case study.
Hume, Miracles and the Many Witnesses Objection (Dec 2018) - Just in time for Christmas, I wrote this analysis of Arif Ahmed's recent defence of Hume's argument against miracles from the 'many witnesses' objection. Ahmed's original paper is quite dense and technical. This was an 'ordinary language' explanation.
As an academic, I’m acutely aware of my numbers. They are the measure of my worth.
As of December 2018, I have published 34 peer-reviewed journal articles (not bad for my career stage?), 12 book chapters (okay, but there are more on the way!), 1 edited collection (should I have more?), and 1 monograph (technically not due for publication until next year but it is important that we count it now). If you count publications on this blog (and I do) then I have more than 1000 ‘other’ ‘non-peer reviewed’ publications, which have been viewed more than 3.5 million times (probably more, but I don’t have access to the figures on other websites). For all this effort, I have just under 270 citations, with a h-index of 9 and an i-10 index of 9 (not good, but I’m a philosopher/lawyer and we don’t do well on these metrics). In addition to this, I’ve been awarded just over €150,000 of research funding in my time (pathetic really, but I’ve applied for and failed to receive several million - don’t forget that!), and I’ve received more media mentions than I care to mention (mostly because I’m ashamed of the majority of them). I’ve taught more than a thousand students but received zero teaching awards. I’ve held one relatively major administrative role, and half a dozen minor ones. In short, after seven years as a full-time, post-PhD academic, I am a bundle of statistics and numbers, none of them very meaningful in their own right, but all of them crucial when it comes to selling myself and my ideas.
I’m also quite disillusioned. As I say to graduate students every year, when asked to give advice on publishing, the numbers shouldn’t matter. They don’t make you happy or make your scholarship any better. Having 34 peer-reviewed journal articles doesn’t make you any happier (or any better a scholar) than having 24. When asked for proof of this, I point to famous examples: Wittgenstein only published 3 things in his lifetime, and one of those was a book review. That didn’t stop him from having an outsized influence on an entire generation of philosophers. The numbers are a distraction from the ideas, the arguments, the intellectual curiosity — the things that got you into academia in the first place.
But it is worth reflecting on why this might be the case. After all, a fixation on numbers does make a difference in other walks of life. If I want to improve my personal best at running, then it is useful to keep track of and try to purposefully improve, my split times. If I want to reduce my weight, then it is useful to keep track of and try to reduce my calorie intake. Numbers really are a metric of success in some walks of life. Why aren’t they (or why don’t they seem to be) in academic life?
Jerry Muller’s short polemic — The Tyranny of Metrics— offers some insight. In this book, Muller presents a tightly argued critique of ‘metric fixation’, a trend that has taken over in the management of education, academia, healthcare, policing and other bureaucratic systems. Metric fixation promises us a more productive and more efficient system, but those of us living under the thumb of the metrically obsessed often don’t see it that way. It’s not that we are lazy and inefficient — at least not all of us; it’s that we find the metrics misleading, distracting, and undermining. We yearn (or at least I yearn) to be free of them.
In what follows I want to briefly set out Muller’s critique of metric fixation, consider how it applies to my life as an academic, and then reflect on three strategies I have found helpful for avoiding the tyranny of academic metrics.
1. Muller’s Critique of Metric Fixation
Metric fixation starts with the best of intentions. The worry is that certain systems, particularly those in the public sector but also some in the private sector, are bloated, inefficient and expensive. The goal is to make them more efficient and effective. The metrics are supposed to do that. They give people clear targets. They introduce something like the discipline of the market to forms of work that are usually removed from such discipline. The result is that workers will be more motivated and self-actualised, and that consumers, service users and stakeholders will benefit as well. It all starts from a good place.
But then things quickly go downhill. Muller’s argument is very easy to grasp. He thinks that the metrics that have been introduced to sectors like education, academia, health, policing, finance, the military and elsewhere, have a tendency to be ‘dysfunctional’. There are two main problems of dysfunction, each of which breaks down into a number of sub-problems (all of these are set out on pages 23-25 of Muller’s book):
(1) The Distortion Problem: The metrics that are introduced tend to distort or distract attention from what really matters (what the true mark of efficiency or effectiveness is). This isn’t simply because the metrics are bad and need to be replaced by better ones (though that might sometimes be the case), but because some forms of success cannot be easily (or ever) metricised. The problem of distortion can manifest in a number of ways:
(1.1) Measuring that which is easy to measure instead of the more complex thing that matters more - This is a big one because most large organisations are complex and so focusing on one thing that happens to be easy to measure is rarely the best way to ensure success.
(1.2) Measuring inputs instead of outcomes - it is usually the results of a project or collective effort that matter, but they are often diffuse and difficult to track, so organisations tend to focus on inputs than can be easily tracked, e.g. hours worked, money spent and so on.
(1.3) Degrading information quality through standardisation - in the effort to create standardised measures that allow for the comparison of performance across individuals and organisations, we often strip away much of the contextual information that is needed to properly understand what is going on. We create an illusion of simplicity and certainty when the reality is anything but.
(2) The Gaming Problem: Once the metrics are installed and people are rewarded for optimising them, they are frequently gamed, i.e. they become an end in themselves and people do whatever it takes (up to and including fraud) to hit their targets. This is obviously a problem because gaming often undermines or contravenes the original purpose of the metric. Again, the problem of gaming can manifest in a number of ways:
(2.1) Gaming through creaming - people focus on the easy cases (clients, problems etc) in order to meet their targets and exclude the tougher cases that might cause them to miss their targets (the name comes from the idea of ‘skimming the cream’)
(2.2) Lowering standards - possibly the same as the above but can be a distinctive problem in education or other sectors where getting people through a system is one of the metrics of success. One of the easiest ways to do this is to lower the standard that people have to attain to get through the system.
(2.3) Omission and distortion of data - leaving out any figures that might undermine your metrics, or classifying/reclassifying cases so that they don’t get included (a particular problem, it seems, in policing where offences get reclassified in order to reduce crime rates).
(2.4) Cheating - going beyond mere distortion and omission and actually fabricating data in order to make it seem like targets have been met or exceeded.
Muller spends the majority of his book documenting how each of these problems arises across a range of sectors. The cumulative weight of this evidence is pretty impressive, though I have to confess that I am not able to critically assess some of the examples. It could be that he is unfair in a few cases, but I am inclined to believe him. Part of the reason for this is that I see the majority of the problems arising both academia in general, and my own life in particular. It’s to my personal experiences that I now turn.
2. Examples of the Tyranny of Academic Metrics
As mentioned earlier, the life of a modern academic is suffused by a panoply of metrics. They are everywhere. The universities in which you work are scored and ranked, your teaching is assessed and evaluated by your students, and your students are encouraged to take endless ‘satisfaction surveys’ to determine how they compare to students at other universities. Your research and skill as an academic is also assessed by various metrics: number of publications in top-ranking journals, number of paper downloads, number of citations (h-indexes and i-10 indexes), number of PhD students, amount of research funding won and so on and so on.
Many of these metrics are of dubious merit. Student surveys that compare student satisfaction across different institutions, for example, often strike me as being of limited value: most students only have experience of one university and one degree programme, and so comparing their satisfaction ratings across different institutions gives you questionable insights. It’s a bit like using fahrenheit and celsius scales to measure temperature in different universities and assuming the numbers are equivalent. And yet institutions are incentivised to optimise these ratings in order to advertise themselves to potential students. This can encourage them to lower standards in order to make students more satisfied, or to focus on these ratings to the exclusion of other important impediments to student well-being. And that’s just one example. In a great paper entitled ‘Academic Research in the 21st Century’, Marc Edwards and Siddhartha Roy document how virtually every performance metric that has been introduced into academia has had some perverse impact. They summarise the problems in the following table (which I reproduce from their article).
These all seem to provide clear illustrations of the problems that Muller outlines in his book: metrics that distort and turn into self-perpetuating games. But rather than talk about these problems in the abstract, I want to consider four examples of distortion and gaming from my own life, each of which I find personally problematic.
The first has to do with research publications. In the past, I have definitely found myself distracted by the publication game. Here’s the dirty little secret about academia: the vast majority of people you work with, on a day-to-day basis, do not care about the research that you do.* They have neither the time, inclination nor expertise to read what you write. Your research is probably only of interest to a handful of like-minded researchers dotted around the world in other research institutions. You might be lucky enough to work in an institution where there is a concentration of people with a shared research focus. But in my experience that is a relative rarity. Indeed, even people who seem to share research interests with you have their own narrow specialisms (and their own metrics to optimise) and as a result won’t be that engaged with what you do. What they are engaged with, however, are your numbers: how many publications do you have? What’s your citation count?
These numbers become your currency of success within your institution. They determine your reputation (Professor X has 1,000 publications! Isn’t she amazing?). It’s hard not to let your ego get bound up with these numbers. You judge others by their numbers and you judge yourself by them too. I fall into this trap all the time. I’m almost ashamed to admit this, but it's somewhat cathartic to confess that I have spent hours browsing through the websites of colleagues to see how far ‘ahead’ or ‘behind’ them I am in the publication game. This is a problem because publication numbers are not what really matters. What really matters is how accurate, persuasive, insightful, original, explanatory, comprehensive (etc) the ideas/arguments/theories contained within those publications are.
At least, that’s what should really matter. But you get distracted from writing high quality research in order to optimise your metrics. As recent scandals have suggested, it is possible, with enough perseverance and pigheadedness to get any old rubbish published in a peer-reviewed journal. I know I have. There are several things I have published that I think are substandard and that I should have spent more time working on. But once you become obsessed with the game, you cannot afford the luxury of quality. You have to act now lest you fall behind your self-imposed standards of productivity. “I published 4 papers last year so I have to publish at least as many again this year, otherwise people will think I’m a slacker!”
The second example has to do with research funding. This is, historically, a bigger deal in the hard sciences than it is in the arts, humanities and social sciences. But it is becoming a big deal there too. Publications are all well and good, but to be truly successful as a modern academic, you have to think of yourself as being akin to a startup CEO. You have to rake in millions of pounds/euros/dollars in research funding to be counted among the elite. To do this, you have to spend long stretches of time dreaming up multi-year projects that can justify those millions. What’s bizarre is that universities themselves see this as a core metric of success and will often invest considerable resources in helping you out in this process. They may send you for costly and nauseating corporate training, and they will usually have dedicated staffs and offices to help you with grant writing and interviewing. Now, as I pointed out above, I haven’t been that successful in the grant-winning game, but I have become increasingly invested in it and have won some small pots of funding. These pots of funding have covered my PhD, two small projects, and one longer 18-month project. Furthermore, and perhaps more significantly, I have been shortlisted for some large grants. For example, last year (2018) I was shortlisted for an ERC starter grant worth just over €1 million euro. I’m proud to report that I failed spectacularly at the presentation and interview stage.
I have mixed feelings about grants. Getting money can be great. Not only is it a reputation builder, it is also genuinely useful to have money to be able to run workshops and events, and to buyout your time so that you can focus on certain research questions. But the grant-winning game also has significant downsides. People care mainly about how much funding you have ‘won’ not what you do with that funding. It’s a classic example of the ‘measuring inputs not outcomes’-fallacy outlined above. Universities set ambitious targets for research funding, but often don’t provide much support to grant winners once their projects are up and running. This is a disaster for someone like me who is bad at managing anything other my own time (and I struggle a lot with that too). What’s more, there is relatively little follow-up to see that you have done what you promised to do. Sure, you have to write progress reports and spend the money appropriately, but as long as you avoid outright fraud, you should be able to write semi-plausible project reports that don’t raise too many red flags. You thus end up managing your project as a series of punctuated panics: long periods of frustration and procrastination, followed by flurries of activity as reporting deadlines approach.
The funding game has other downsides too. It generates a lot of wasted competition: lots of time and money is spent in trying to win ultra-competitive grants. The nature of the game is such that the vast majority of that time ends up being wasted (at least 90% of people won’t get the funding). The high rejection rates are the mark of how prestigious the grants are. All that competition might be justified in the sciences on the grounds that there are some projects that are genuinely better than others and require lots of expensive equipment, but in arts, humanities and social sciences I’m not so sure. I suspect the time and money dedicated to winning grants would be better spent on actual research. And there is another big problem with the grant game too: it contributes to the casualisation of labour in higher education, and the over-supply of PhDs and postdocs. An ambitious researcher is now encouraged to view it as a mark of success to ‘win’ funding that employs other people to do work for them and in lieu of them on a temporary basis. On a case-by-case level this looks like a win-win: more jobs and more money. But at a structural level things look much less rosy.
The third example has to do with teaching. Like most of my colleagues, I have a healthy degree of scepticism when it comes to teaching evaluations. I think they have some merit. For example, if there are serious problems with your course, the student evaluations can reveal them to you (though there should be other avenues for this). But outside those extreme cases, I think they are practically worthless. Students aren’t always the best evaluators of their own educations. Courses that are difficult often score poorly on evaluations because evaluations capture students’ immediate feelings about a course. But these difficult courses can have the most positive long-term impact. The problem is that it is too difficult to assess those long-term impacts as a matter of course (though some researchers have tried to do so and confirmed common sense). They also provide disgruntled students with an excuse to vent their (unwarranted) frustrations with you (and research suggests that women often bear the brunt of this). Furthermore, if the evaluations are good, they do little more than massage your fragile ego.
Indeed, in some ways I find this last feature of student evaluations to be the most pernicious. Most of my teaching evaluations are positive (I’m genuinely not trying to brag). Some students hate me, to be sure, but the majority say that they enjoy my lectures and find them to be enlightening, well-organised and, occasionally, entertaining. That all sounds great. What bothers me is how much I have come to rely on these positive comments for my own self-worth. I anticipate them eagerly after every teaching evaluation. If I don’t get them (or don’t get as many as I think I deserve) I get upset about it. I also then fixate upon the few negative comments (“JD is a cunt”, “John Danaher is a very boring man”)** and let them get me down. In the end, I feel a need to ingratiate myself to my students to boost my metrics. I want to give them more handouts and easier assignments, even though I know that this may not be in their long-term interest. And, of course, the evaluations are not a purely private affair between myself and my students: my institution cares about them too and encourages me to use them in my own self-promotion. So I’m incentivised to optimise my evaluations for reasons that are unrelated to my fragile ego.
The fourth and final example has nothing to do with individual metrics and the games they generate. It has to do with the net effect of working in an environment in which there are so many metrics, and where you are rewarded and incentivised to optimise them all: you end up being spread too thin. You cannot possibly optimise every single metric. There are some opportunity costs. But how do you pick and choose? Unless you are laser-focused and harbour no doubts about the merits of what you are doing, it’s very easy to fall between all the cracks. To end up fragmented, distracted and perpetually frustrated.
3. Breaking Free from the Tyranny of Academic Metrics
All of this paints a negative picture. Is there any light at the end of the tunnel? Maybe. First, let me say that things aren’t as bad as I am making them out to be. I’m being deliberately provocative with my pessimism. I don’t feel disillusioned, distracted or disheartened all the time. I only feel like that some of the time, usually when I fall prey to my worst instincts. The rest of the time I approach my metricisation with a degree of irony and stoicism.
Nevertheless, I think finding an actual escape from the tyranny of academic metrics is hard. Part of the problem is institutional/structural: these are the metrics that are used to determine your employability and promotability within academic institutions. And part of the problem is intrinsic to certain academic disciplines: there are no criteria of success that obviously trump the metrics. In certain mathematical disciplines and hard sciences, it is possible to have laser focus. If your life’s mission is to prove the Riemann hypothesis, then you have a pretty clear standard for your own success. But in other disciplines things are much less clearcut. You want your ideas to achieve some degree of acceptance and influence within your chosen discipline, but beyond that you’re not really sure what it is that you are trying to do. It’s easy to fall back on the institutionally imposed metrics because they are at least tractable, even if they are misleading and disheartening.
So what can you do? I can only speak to my own experience. I find a combination of three strategies to be useful:
Achieve a reasonable ‘leave me alone’ credibility on the major metrics: In other words, score sufficiently highly on some key metrics that no one is going to question what you are doing. To use myself as an example, I feel I have done this on teaching and research. My student evaluations are sufficiently positive that no one is going to call my competence as a teacher into question; I have published enough (I think) that people don’t question my capacity as researcher (particularly since the majority of them aren’t going to read what I have written); and I’ve also won a few bonus points when it comes to research funding and non-academic impact. This gives me some breathing space to do what I most like to do.
Find some metrics that you can live with and do your best to ignore the rest: The abundance of metrics, and the lack of clear criteria for success, can be turned to your advantage. Since no one is really sure what the ultimate measure of success is, and since new metrics are being invented all the time, you have some flexibility to develop and play ‘games’ that appeal to you, and that also make you stand out from the crowd. For example, I genuinely enjoy reading, thinking and writing (not necessarily in that order!). There are plenty of metrics that I can use to pursue those ends that aren’t tied to traditional academic publishing. I’ve found, for example, that my limited success as an academic blogger generates metrics (page views per month, number of downloads per podcast) that have resonated with my employers. Since I’ve achieved reasonable credibility in other metrics, these metrics are often weighted quite favourably in performance reviews and job interviews. This does, admittedly, require a degree of imagination and flexibility in the application of assessment criteria, but it is a potential boon to the more independent-minded researcher.
Use regulative ideals or grand projects to motivate yourself, not metrics: This is the most cringeworthy strategy, and I apologise for that, but it is also the most important. To avoid distraction and frustration I think it is essential not to lose sight of the grander projects and ambitions that motivate your academic life. This doesn’t necessarily mean getting caught up in some messianic revolutionary project (though some of my colleagues do have such ambitions and they seem to work for them); it just means pursuing something other than personal, metricised success. My grand ambitions, for example, include ‘learning more about the world’, ‘pursuing my curiosity wherever it may lead’, and ‘mapping and evaluating the possible futures of humanity’. These projects do not generate simple metrics of success. But I like to constantly remind myself that they are the reason why I’m doing what I’m doing.
H-indexes be damned.
* Yes, I know that this translates more generally: the vast majority of people (full stop) will not read anything you write. ** Both real. For American readers: ‘cunt’ has a less gendered meaning in British/Irish slang. It’s probably most often used to negatively describe a man. It can however be used in a positive sense ( as in “He’s a funny cunt, isn’t he?”). However, I’m pretty sure that the intended meaning was not positive in this case.
In this episode I talk to Michele Loi. Michele is a political philosopher turned bioethicist turned digital ethicist. He is currently (2017-2020) working on two interdisciplinary projects, one of which is about the ethical implications of big data at the University of Zurich. In the past, he developed an ethical framework of governance for the Swiss MIDATA cooperative (2016). He is interested in bringing insights from ethics and political philosophy to bear on big data, proposing more ethical forms of institutional organization, firm behavior, and legal-political arrangements concerning data. We talk about how you can use Rawls's theory of justice to evaluate the role of dominant tech platforms (particularly Facebook) in modern life.
You download the show here or listen below. You can also subscribe on iTunes or Stitcher (the RSS feed is here).
Show Notes
0:00 - Introduction
1:29 - Why use Rawls to assess data platforms?
2:58 - Does the analogy between data and oil hold up to scrutiny?
7:04 - The First Key Idea: Rawls's Basic Social Structures
11:20 - The Second Key Idea: Dominant Tech Platforms as Basic Social Structures
15:02 - Is Facebook a Dominant Tech Platform?
19:58 - How Zuckerberg's recent memo highlights Facebook's status as a basic social structure
23:10 - A brief primer on Rawls's two principles of justice
29:18 - Dominant tech platforms and respect for the basic liberties (particularly free speech)
36:48 - Facebook: Media Company or Nudging Platform? Does it matter from the perspective of justice?
41:43 - Why Facebook might have a duty to ensure that we don't get trapped in a filter bubble
44:32 - Is it fair to impose such a duty on Facebook as a private enterprise?
51:18 - Would it be practically difficult for Facebook to fulfil this duty?
53:02 - Is data-mining and monetisation exploitative?
56:14 - Is it possible to explore other economic models for the data economy?
59:44 - Can regulatory frameworks (e.g. the GDPR) incentivise alternative business models?
If we are to take religious believers seriously, then miracles really do happen. Indeed, several of the world’s leading religions are founded on miracle claims. Christianity is probably the most famous example of this, with the testimony concerning Jesus’s death and bodily resurrection being central to that religion’s origin. But given that we are separated from that alleged miracle by almost two thousand years (if we take the historical consensus seriously, then Jesus died around 30 CE), how can we have any confidence in its occurrence? All we have are a handful of indirect written reports, none from an actual eyewitness to the event, though several claiming to be founded on the testimony of eyewitnesses. To me, at any rate, this seems like a thin reed upon which to hang the eternal fate of one’s soul.
But suppose we did have direct eyewitness testimony of the resurrection. Suppose (per Paul’s letter to the Corinthians) we have 500 eyewitnesses all testifying to its occurrence. Should we believe them? David Hume famously argued that we shouldn’t. In his essay ‘Of Miracles’ he argued that it is only in exceptional circumstances that we would have reason to believe in miracles on the basis of eyewitness testimony. I have covered the exact details of Hume’s argumentin several previous articles. I won’t rehash them here. The gist of his view is that, given the general improbability of a miracle, and given the known unreliability of eyewitness testimony (people are known to lie or misinterpret or delude themselves as to what really happened), we would only have reason to believe in a miracle, on the basis of eyewitness testimony, if the falsity of the eyewitness testimony is more improbable than the miracle itself.
The debate about Hume’s argument has become increasingly sophisticated and mathematised over the years. One cadre of critics — including Charles Babbage, Rodney Holder and John Earman — have taken issue with the application of Hume’s argument to cases involving multiple independent witnesses. They’ve argued that if you have a sufficient number of independent witnesses, then no matter how low a prior probability you assign to the occurrence of a miracle, it is possible to drive the posterior probability of the miracle’s occurrence arbitrarily high by increasing the number of witnesses.
There is a formal proof of this critique, but it is relatively intuitive. Suppose you did have 500 hundred genuinely independent witnesses (i.e. they haven’t colluded with one another or been influenced by one another) and suppose each individual witness is more likely (even if only marginally) to be telling the truth about what they saw than not. Suppose then that when you talk to them, they all say the same thing: they once saw a dead guy and then saw him alive again. In such a case, even if you were really sceptical at the outset, you’d be hard pressed to retain your scepticism by the end. The improbability of them all getting it wrong will surely be greater than the improbability of the miracle. As Babbage puts it in his critique of Hume:
[I]f independent witnesses can be found, who speak truth more frequently than falsehood, it is ALWAYS possible to assign a number of independent witnesses, the improbability of the falsehood of whose concurring testimony shall be greater than that of the improbability of the miracle itself.
This would seem to scupper Hume’s argument since most religious miracle claims purport to be based on the testimony of multiple witnesses. Reasoning of this sort is what led John Earman to conclude that Hume’s argument was an ‘abject failure’ in his 2000 book Hume’s Abject Failure. But is this actually fair? It turns out that the devil is in the detail. What Babbage et al argue is correct in the case of independent witnesses, but it turns out that it is pretty difficult to achieve genuine independence. Indeed, it’s likely that there is no real world case that actually meets the formal requirements of independence. Consequently, Hume’s argument retains some relevance to this day.
This is what Arif Ahmed argues in his 2015 paper ‘Hume and the Independent Witnesses’. Ahmed’s paper is quite technical, peppered with Bayesian equations and proofs. What I’m going to try to do in this post is provide a simple, non-technical explanation of the argument it contains. In developing this non-technical explanation, I’ve drawn heavily from the paper itself and an interview that Ahmed did about its contents. I found watching/listening to the latter helped when I went back into the paper itself. So much so that I’ve embedded the video at the end of this post.
Anyway, Ahmed’s critique hinges on two problems with establishing independence. Let’s go through them both.
1. The Difficulty of Attaining True Independence
The first problem for the many witnesses objection is the practical difficultly of proving that witnesses are truly independent. By ‘true independence’ I mean a scenario in which the every eyewitness is causally sealed off from every other eyewitness in such a way that you can plausibly rule out the possibility that they have colluded with one another to get their stories straight, or that they have been directly or indirectly influenced by what another witness has said in such a way that they reinterpret what they saw, or pretend that they saw something when they really did not.
The inability to prove true independence turns out to be a big problem when it comes to the real world evaluation of witness testimony. It’s something that lawyers and police officers grapple with all the time. If I say I saw someone dressed in clown mask, running away from the jewellery store, clutching a bunch of diamond necklaces, then you might be more inclined to say that you saw the same thing, even though you really didn’t see what the person was wearing, and only saw them out of the corner of your eye. We are all subject to subtle and not so subtle forms of social influence that contaminate our testimonies. Some of us might retain our independence in the face of external influence but, as Ahmed puts it, some of us might be ‘falsehood suggestible’ (i.e. inclined to modify our testimony to cohere with the false testimony of others) and some of us might be ‘falsehood counter-suggestible’ (i.e. inclined to modify our testimony to go against the consensus view out of contrarianism). Unless you could single out the suggestible witnesses and remove them from the pool of witness, or unless they perfectly counterbalanced one another, their presence within the pool of witnesses would undermine the credibility of the total pool of witness testimony. You could no longer be confident that the improbability of falsehood was less than the improbability of a miracle.
Ahmed doesn’t spend much time on this problem of establishing true independence in his paper. He focuses more on another kind of independence (namely: conditional or formal independence). We’ll turn to that in the next section. But the difficulty of establishing true independence is something that Earman himself admits, and that Peter Millican has made much of in his criticisms of Earman’s work. As Millican explains:
Without contesting Earman’s technical results, one can dispute the seriousness of [the many witnesses objection] since most of his discussion seems to ignore entirely the epistemological dimension of how one could possibly know that the witnesses in question are genuinely independent.
And the reality is that in the case of something like the eyewitness testimony to Jesus’s resurrection, we do have reason to doubt the true independence of the testimony that is adduced. For starters, we don’t actually have five hundred independent eyewitness reports. All we have is Paul’s claim that there were five hundred witnesses - that’s one report not multiple reports. And likewise the four Gospels are not entirely independent of one another. We know that they were written in a chronological sequence (from Mark to John) and that later gospel writers were influenced by earlier gospel writers (and by a pre-existing oral tradition). So we have reason to suspect that the actual pool of witness reports that we actually have is contaminated in such a way that we cannot be certain of true independence. This is likely to be the case with many other real-world cases of witness testimony.
2. The Difficulty of Attaining Conditional Independence
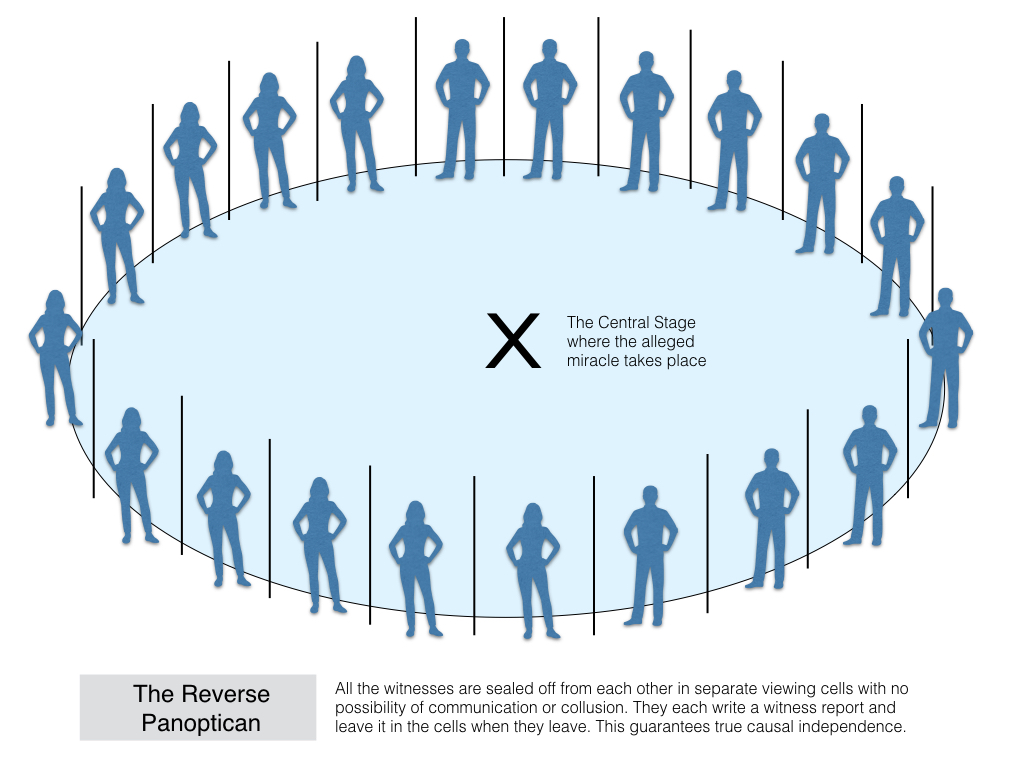
The second problem for the many witnesses objection is more technical and formal. It starts by trying to concede as much as possible to the objection and trying to conjure up a case in which we can be really confident that the witnesses have not causally influenced each other. Ahmed has a nice thought experiment that allows for this. It is based on a reversal of Jeremy Bentham’s famous Panopticon design for a prison. In Bentham’s Panopticon you have a circular array of prison cells that can all be viewed by a single guard from a central watchtower. The prisoners are, consequently, under constant threat of surveillance. Imagine if you flipped that design so that you have hundreds of hermetically-sealed viewing cells all looking at a central stage or platform upon which some, alleged, miracle is performed. That might allow for true independence. I’ll leave Ahmed explain the idea:
The Reverse Panopticon Thought Experiment: "[R]eplace the observation platform with a large stage that can be seen from each cell; but still no cell communicates with any other. Some self-proclaimed prophet has forecast a miracle on this stage at a specific date and time. In each cell we place a witness possessed of scepticism, integrity, sincerity, and general good sense; the witnesses have never been in direct or mediated contact of any sort. In each cell are a pencil and a pad. We ask each witness to observe the stage at the time in question, to write down what happened on it, and then to depart leaving the report in the cell, which automatically locks behind her. We later collect the reports, and it turns out that each one is to the effect that a man weighing about 150lbs walked across the surface of a large tank of liquid water without any other means of support."
This set-up would seem to allow for the true causal independence of the witnesses. There is no possibility of them colluding with one another in the drafting of their testimony. Their reports would be uncontaminated by social influences. Could we then be confident that a miracle really occurred?
Ahmed says ‘no’. The reason for this is that even in such a case the witness testimony would not be genuinely independent. It would fail to be conditionally or formally independent. This is where things get a little bit technical. There are two formal conditions of independence that the testimony would have to meet in order for the many witnesses objection to work. These conditions don’t have to do with the causal relations between the pool of witnesses but, rather, the formal relation between the testimony and your degree of belief in the testimony (at least that’s how I understand it: the kind of independence in question is one that is conditional on your beliefs). The two conditions are:
Independence of True Positives (ITP): If you know that the miracle did occur, then no amount of (true) positive testimony to that effect from a sequences of witnesses (W1…Wn) should increase or decrease your confidence that the next witness’ (Wn+1) testimony will be positive.
Independence of False Positives (IFP): If you know that the miracle did not occur, then no amount of (false) positive testimony to that effect from a sequence of witnesses (W1…Wn) should increase or decrease your confidence that the next witness’ (Wn+1) testimony will be positive.
It might be difficult to wrap your head around these two conditions. After all, they ask you to project yourself into a situation that you are clearly not in. The whole point is that we don’t know whether the miracle occurred or not, and that we are using the testimony to establish what we should believe. And yet to understand these conditions you have to suppose that you do know whether it occurred or not. This seems odd. But the point here is that these are purely formal conditions of independence and they apply even if you do know what the reality is. The basic point that both conditions make is that witness testimony should be uncorrelated given that the miracle has/has not occurred. And, for what it is worth, Earman accepts that both conditions need to be met for the multiple witnesses objection to apply to Hume’s argument.
The problem is that they are unlikely to be met, even in a case like the reverse panopticon thought experiment. Why is this? The issue is that when you are assessing the validity of a hypothesis, given some eyewitness testimony, you are unlikely to be assessing that hypothesis in isolation from all other hypothesis. There are other hypothesis in the mix too. In the reverse panopticon case, we can suppose that there are two main hypotheses on the table (there could be more and the argument would still apply): (i) that there was a genuine miracle (i.e. someone really did walk on water) and (ii) that there was a really good magic trick/illusion (i.e. that it was only made to look like someone did). When assessing the eyewitness testimony, both hypotheses will be affected by a continuous stream of testimony to the effect that a miracle occurred, such that conditional independence does not hold true.
Think about it like this. Suppose you were the one who actually appeared to walk on the water so you know for sure whether it was an illusion or a genuine miracle. Suppose it was an illusion and you go and investigate all the eyewitness reports. The first report suggests that a genuine miracle took place. What would this do to your beliefs? Well it would probably convince you that the illusion you just performed was good enough to fool one person and so your confidence (credence) in the next eyewitness report claiming that a genuine miracle took place, would increase slightly. In other words, you’ll be more likely to think that the illusion fooled the next person. This process would continue as you proceeded through the evidence, raising your confidence that the next report will be positive concerning the occurrence of the miracle, and thereby confirming your belief that you performed a really good illusion. The IFP condition would not be met in this case. The same thing would happen if it was a genuine miracle. In that case, every time you examined an eyewitness report claiming that a genuine miracle took place you would become more convinced that the next report would say the same thing. The ITP condition would not be met in this case.
The general phenomenon at play here is something that Ahmed calls true positive and false positive ‘projectibility’. In any pool of human eyewitness testimony, the presence of a stream of true positive testimony to the effect that an event E occurred is likely to increase your confidence that the next bit of testimony will also give a true positive report; and, likewise, the presence of a stream of false positive testimony to the effect that E occurred is also likely to increase your confidence that the next bit of testimony will also give a false positive report.
This creates a major problem when it comes to assessing a pool of causally independent eyewitnesses when you don’t know whether the event to which they are testifying actually occurred. Go back again to the reverse panopticon case. Suppose you don’t know whether a genuine miracle or a really good illusion took place. You weren’t involved in the event at all. The only thing you have to go on is the eyewitness testimony. Suppose, further, that since you are a sceptic about miracles, your prior probability is that it is more likely (even if only marginally) that an illusion took place. Now, as you examine the pool of uniformly positive eyewitness testimony, something interesting will happen. Your confidence that a genuine miracle took place will go up (since that is consistent with uniform positive testimony) but so too will your confidence that a really good illusion took place (since that is also consistent with uniform positive testimony). In fact, your confidence in the latter will increase more since it started out slightly ahead. Ahmed refers to this, somewhat awkwardly, as the ‘speed’ at which you increase your credence in the relevant hypotheses: your credence in the illusion will go up faster than your credence in the miracle.
So, because true positive and false positive projectibility undermine conditional independence, and because you start off from a marginally sceptical position about the truth of a miracle given some eyewitness testimony, the existence of many witnesses, all testifying to the occurrence of a miracle, should not, by itself, cause you to believe in the occurrence of the miracle — at least not in the typical case. This means that the many witnesses objection fails, even when we imagine a highly unrealistic scenario in which we can guarantee true (causal) independence among the witnesses.
3. Some Qualifications and Limitations
That’s the ‘ordinary language’ explanation of Ahmed’s argument. There is a more formal proof in the original article. But the proof is only as good as the assumptions underlying it and there are a number that ought to be emphasised because they highlight some important limitations to the argument.
The first is that the argument is a Bayesian one, i.e. it is about the subjective probabilities you should attach to the belief in the miracle, not about the actual objective probability of the miracle’s occurrence. This is an obvious enough limitation: we can’t really assign objective probabilities to miraculous events. But because the argument is about subjective probabilities, its implications would actually change depending on the subjective prior probability you attach the likelihood of a miracle occurring. If you are someone who thinks it is more likely that a miracle occurred than (say) a really good illusion, then the projectibility of the testimony would lead you to favour the belief in the miracle’s occurrence over the belief in the really good illusion. In other words, it matters which belief starts out ‘ahead’ in your subjective probability distribution.
This, however, isn’t a very serious limitation. As Ahmed points out, Hume’s original argument was only supposed to apply to those who are marginally sceptical about the occurrence of miracles. He was asking whether testimony would ever be enough to shift that sceptic from their position of doubt. If you are already inclined to believe in miracles, then, of course, more testimony is likely to increase the subjective probability you attach to their occurrence. But, even still, Ahmed suggests that for any given miracle claim, the typical religious believer, should really start out as a marginal sceptic in its actual occurrence. After all, the whole point about miracles is that they are very rare, and that it is more likely that a claim is false than that it is true. People make miracle claims all the time, and more importantly people from different religions make them all the time; the typical religious believer is usually only willing to accept a small subset of those claims.
The second limitation is that the argument only applies to cases in which the testimony all relates to the same event and comes from the same source or origin. This is why the set-up of the reverse panopticon thought experiment is important. In that case, all the witnesses are looking at and reporting on the same event. This means the reports that you read can be genuinely compared with one another for consistency. It also means that they don’t each provide a different kind of evidence for the same event: they are all just more of the same thing. If instead of having multiple independent eyewitness reports, you had multiple independent types of evidence, then the situation would be rather different. The pool of evidence wouldn’t have the property of projectibility that was outlined above. In that case, one of the multiple lines of evidence might ‘knock out’ one of the hypotheses that is consistent with eyewitness testimony, and not another. This might result in more confidence being attached to the remaining hypothesis. This is true if the eyewitness testimony is of a different type as well. For example, if instead of all the witnesses looking at the stage upon which the person walks on water, some of them are involved in setting up the stage and didn’t see any obvious trickery, and some were positioned underneath and above the water tank and couldn’t see any trickery, then you might (and I emphasise might since all that testimony could still be consistent with an illusion) have more reason to believe that a miracle actually occurred.
This second limitation is not surprising and is, actually, quite intuitive. In science and law we already accept that it is better to have multiple different kinds of evidence converging on the same result. For example, in a murder case, it is much more likely that someone committed a murder if you find their DNA at the scene, the murder weapon with the victim’s DNA in their house, and you have multiple eyewitnesses seeing them leave the scene of the crime, than if you only have one of those types of evidence. For example, you could have multiple different labs testing the DNA evidence from the crime scene, but no matter how many reports you get back confirming that it was indeed the suspect’s DNA that was found at the crime scene, it wouldn’t make it more likely that the suspect committed the murder, if it turned out they had a perfectly good alibi explanation for why their DNA is at the crime scene.
In fact, Ahmed thinks that one of the strengths of his argument is that it explains why multiple different lines of evidence are a good thing. As he points out, it is something of a puzzle, on Bayesianism, why having multiple different kinds of evidence is better than have multiple different versions of the same kind of the evidence. After all, if each bit of evidence raises the posteriori probability of a given hypothesis, it shouldn’t really matter where it came from. The projectibility phenomenon helps to explain why this is actually a problem.
Despite its limitations, Ahmed’s argument is still pretty neat. It shows just how difficult it is to have genuinely independent witnesses. They don’t just have to be causally independent from one another; they also have to be conditionally independent. It’s very unlikely that any real world case, involving testimony to a miracle, will satisfy both kinds of independence. What’s more, the argument applies more generally to any case in which you have multiple different versions of the same kind of evidence, and at least two hypotheses that are consistent with that evidence, one of which has a higher prior probability than the other. It’s not just about eyewitness testimony. In the limit, it could apply to the evidence from your own senses or the evidence from some external detection device. Ahmed discusses this in the video below. And I’ll leave you now to watch it if you so desire.
I recently participated in a workshop on ‘Algorithmic Governance in Transport’ at the OECD in Paris. The workshop was organised by the International Transport Forum (ITF), which is a sub-unit of the OECD that focuses on transport policy and regulation. The workshop featured a wide range of participants, mainly drawn from industry, government and public policy, with a handful of academics like myself thrown in for good measure. The purpose of the workshop was to consider how algorithmic governance technologies might be regulated, or be used for regulating, the transport sector.
The meeting was conducted under ‘Chatham House’ rules, so I am honour-bound not to report on what particular people said at it. But it was an interesting event and I thought it might be useful if I could put some shape on my own thoughts on the topic in its aftermath. That’s what this post tries to do. I should confess at the outset that, although I have written and thought a lot about algorithmic governance over the past few years, I haven’t really thought that much about its applications to the transport sector. I’ve been more interested in its role in bureaucratic decision-making, finance and criminal justice. Nevertheless, one thing that struck me at the workshop was how similar the issues are across these different sectors. So I think there are some important general lessons about algorithmic governance that can be gleaned from the discussion of transport below (and, since I’m not an expert on transport, much that I probably leave out that should be included).
I’ll divide the remainder of this post into three main sections. First, I’ll talk about the various applications of algorithmic governance technologies in transport. Second, I’ll sketch out a general framework for thinking about the regulation of algorithmic governance technologies in transport. And third, I’ll highlight my key ‘take aways’ from the workshop. I want to be clear that everything I am about to say is my own take on things and does not represent the views of anyone else at the meeting nor, of course, those of the ITF and the OECD.
1. Algorithmic Governance in Transport
I’ve been defining ‘algorithmic governance’ for years. I still don’t know if I am getting it right. I always point out that I use the term in a restrictive sense to refer to a kind of control system that is made possible by modern digital technologies. I do this because the word ‘algorithmic’ can be applied quite generally to any rule-based decision-making process. After all, an algorithm is just a set of instructions for taking an input and producing a defined output. If you applied the term generally, then pretty much any bureaucratic, quasi-legal management system could count as an algorithmic governance system. But this would then obscure some of the important differences between these systems and modern, computer-based systems. It’s those differences that interest me.
This is something I wrote about at greater length in my paper ‘The Threat of Algocracy’, where I followed the work of the sociologist A.Aneesh in distinguishing bureaucratic governance systems from algorithmic ones. To cut to the chase, the way I see it, an algorithmic governance system is any technological system in which computer-coded algorithms are used to collect data, analyse data, and make decisions on the basis of that data. Algorithmic governance systems are usually intended to control, push, nudge, incentivise or manipulate the behaviour of human beings or, indeed, other machines or machine components (a qualification that becomes important in the discussion below). So, to put it more pithily, algorithmic governance is, to me, a kind of technology, not a management philosophy or ideology (though it may, of course, be supported by some such belief system).
A classic example of an algorithmic governance system in action — and one that I have used many times before — is the chaotic storage algorithm that Amazon started using to stock warehouses a few years back. This system collects data on available shelf space within a warehouse and allocates stock to that shelf-space on a somewhat random/chaotic basis (i.e. not following a traditional rule such as grouping items according to type or in alphabetical order but rather allocating on the basis of available shelf-space). When human workers need to fill an order, the algorithm plots a route through the warehouse for them. As I understand it, the system has changed in the past few years as Amazon has stepped up the use of robots and automation within its warehouses. Now it is the robots that store and locate shelving units and the humans that do the more dextrous work of picking the stock from the shelves to fill customer orders. If anything, this has resulted in an even more algorithmised system taking root within the warehouses.
Algorithmic governance systems are not all created equal. They vary along a number of dimensions. This is something I have discussed in exhaustive, and probably excessive detail, in my two papers on the ‘logical space’ of algocracy (and I have another one due out next year). The gist of both papers is that algorithmic governance systems vary (a) in terms of the functions they perform (collection, analysis, decision-making): some systems perform just one of these functions, some perform all three; and (b) in terms of how they engage with human participants: some systems require input from human, others usurp or replace human decision-makers. These variations can be important when it comes to understanding the ethical and societal impact of algorithmic governance, but acknowledging them adds a lot of complexity to the discussion.
So what about algorithmic governance in transport? How does it arise and what can it be used to do? I have to talk in generalities here. As is clear from my definition, algorithmic governance systems can be used to collect and process data and make decisions on the basis of that data. These are all functions that are useful in the management of transport systems. Transport is concerned with getting stuff (where ‘stuff’ includes people, animals, goods etc) from A to B in the safest and most efficient manner possible. It uses a variety of means for doing this, including bikes, scooters, cars, trucks, trains, planes and more. There is a lot of transport-related data that is now collected, including information about driver behaviour, machine performance, pedestrians, road surfaces and so on. The assumption is that this data could be analysed and used to create a safer, more efficient and, possibly, fairer transportation system. Some of the obvious uses of algorithmic governance in transport would include:
Analysis and communication of transport-related information to key decision-makers (drivers, pedestrians, traffic planners)
Control of the access to transport systems and the public/spaces these systems utilise (e.g. giving some people preferential access to modes of public transport, parking space; or creating a platform linking private cabs to customers a la Uber and Lyft)
Control of the actual transport system (e.g. automated metro lines, self-driving cars, autopilot systems)
Nudge/regulate transport-related behaviours of humans (e.g. use of speed-tracking signs to encourage drivers to slow down)
There are many more specific applications that we could consider and imagine. These four general applications will suffice, however, for understanding why people might care about the ‘regulation’ of algorithmic governance in transport. That’s the topic I turn to next.
2. A Framework for Thinking about Regulation
The focus of the OECD workshop was on coming up with guidelines for the regulation of algorithmic governance systems in transport. The organisers divided the discussion into three main subject themes: (i) the creation of machine-readable and implementable regulations; (ii) regulation by algorithms and (iii) regulation of algorithms. I found this breakdown initially confusing. I wasn’t sure if the distinctions could be sustained. By the end of the workshop I decided that it did have some utility, but that some clarification was needed, at least if I was to make sense of it all.
The problem for me was that word ‘regulation’ is somewhat ambiguous in meaning. Sometimes we use the word to refer, generally, to any attempt to control and manage behaviour so that it conforms with certain preferred standards. This general conception of regulation is agnostic as to the means used to ensure compliance with the preferred standards of behaviour. Other times, however, we use the word to refer to a particular kind of control and management of behaviour, specifically the use of linguistically encoded rules and regulations (‘You must do X’, ‘You must refrain from Y’) that communicate preferred standards and are enforced through some system of monitoring and punishment.
This ambiguity of meaning creates a problem when it comes to algorithmic governance in transport because, given my previous definition and understanding of an algorithmic governance system, it is possible for such systems to be both subjects of regulation, as well as means by which we implement regulation. In other words, you could have a regulatory code (a set of rules and standards) that you think all algorithmic governance systems should abide by, and you could, at the same time, use the algorithmic governance system to regulate the behaviour of both the people (and the machines/physical spaces) at the heart of the transport system. Understanding and appreciating the dynamics of this ‘two-faced’ nature of algorithmic governance systems in transport is, I think, important when it comes to thinking about the regulatory questions. This is true in all other domains in which algorithmic governance systems are used as well.
So the bottom line is that we need some framework for clarifying how to think about algorithmic governance and regulation, given the ‘two-faced’ nature of algorithmic governance systems in relation to any regulatory system. Now lots of people have tried to develop frameworks of this sort before (Karen Yeung has a particularly good one, for example), and I don’t necessarily want to reinvent the wheel, but as result of what I heard at the workshop, I sketched out one that I thought was useful. Here’s my attempt to explain it.
The framework has three parts to it. It proposes that when you think about regulation and the algorithmic governance of transport (or anything else) you need to think about three separate things: (i) the nature of the regulatory system that sits ‘above’ or ‘around’ the algorithmic governance system; (ii) the nature of the algorithmic governance system itself and the functions it performs in the transport sector; and (iii) the impact/effects of that algorithmic governance system. This is illustrated in the diagram below.
Let’s go through each element of this framework, starting with the nature of the regulatory system that sits above or around the algorithmic governance system. You’ll have to forgive the metaphorical language I’m using to describe this aspect of the framework. The basic idea is that any algorithmic system that is used in transport management and control will sit within some broader regulatory context. There is no aspect of modern life that is not subject to at least some regulation. There will be some set of linguistically encoded rules that participants within the transport system will be expected to abide by. This ruleset will cover, to a greater or lesser extent, the behaviour of all the major participants in the transport system, including service providers, commuters, sellers, local governments and so on. Any algorithmic governance system introduced into the transport sector will, at a minimum, raise questions about the ruleset and the regulatory context. Its introduction will be a ‘disruptive moment’ and may lead to ambiguities or uncertainties about the applicability of that ruleset to the new technology and the powers of those charged with monitoring and enforcing it. This is true for all new technologies. To figure out how disruptive it really is, you’ll have to ask some important questions: what does the broader regulatory context look like? Is there a single regulator responsible for all aspects of transport (unlikely) or are there lots of regulators? Do they have sufficient expertise/personnel/resources to address the new technology? Can they effectively enforce their rulesets? Are the rules they use sufficiently detailed/robust to apply to the new technology? Should they apply to the new technology? In short, is the broader regulatory context ‘fit for purpose’?
This brings us to the second aspect of the framework: the algorithmic governance system itself. This is the technological management and control system that is intervening in the management of transport. Getting clear about the nature of that system, and the functions it can perform is crucial when it comes to figuring out its regulatory impact. What exactly is it doing and what is it capable of doing? Is it publicly or privately owned? Could we use the system to better implement and monitor the existing regulatory ruleset? Does it render parts of that regulatory ruleset moot? Does it sit in an unwelcome regulatory ‘gap’ that means it is exempt from regulations that we really think it ought not to be exempt from? The last question is particularly important because many new technologies can be used to perform a kind of ‘regulatory arbitrage’, i.e. enable companies to make money by avoiding a regulatory compliance burden faced by some rival. Arguably, this is exactly what made ride-sharing services like Uber and Lyft successful at the outset: they sat outside existing regulations for the taxi-trade and so could operate at a reduced cost. They had other advantages too, of course, and as they have become more successful regulators have swept in to fill the regulatory gaps. This is the natural progression, for better worse. It is important, however, that when thinking about this second aspect of the framework we don’t lose sight of the fact that algorithmic governance systems are not just things that need to be regulated or that need to comply with regulations, but are also things that can regulate behaviour in more or less successful ways. A well designed, smart transport information system, for example, can make commuting much more pleasant and effective from the commuter’s perspective. We may not want an existing and inflexible set of regulations to hinder that.
And this, naturally enough, brings us to the third aspect of the framework: the effects of the algorithmic governance system on the real world. It is these effects that play the crucial role in determining how the system should be regulated and how it can be used to regulate. Algorithmic governance systems are often sold to us on the basis that they can make the management and control of technology or human behaviour more efficient, more effective and generally more beneficial. Fitter, happier, more productive and all that jazz. These putative benefits may be quite real and may persuade us to adopt the system (or accept it, if it has already been adopted). But algorithmic governance systems usually have certain risks associated with them and it is important that these are addressed if the system is going to be adopted. These risks are somewhat generic, but manifest in slightly different ways in different contexts. There are six such risks that I thought about when considering the impact in transport:
Security/safety: Is the system actually safe and secure? Is it vulnerable to hacking or malicious interference? Does it increase the risk of accidents? This strikes me as being a big issue in the transport sector. People won’t like to use automated transport management systems if they are accident prone, buggy, or open to malicious hacking.
Data protection/privacy: Does the system respect my rights to privacy and data protection? Obviously, this is a long-standing issue in debates about algorithmic governance since such systems are usually reliant on data collection and surveillance. In Europe, at any rate, there is a reasonably comprehensive set of data protection regulations that any algorithmic governance system will need to abide by in its operation and management.
Responsibility/liability: If something does go wrong with the system, who foots the bill? Who is to blame if a self-driving car gets into an accident or if a traffic monitoring system gets hacked and the data is leaked to third parties? Some people worry about the possibility of responsibility ‘gaps’ arising in the case of complex and autonomous algorithmic governance systems. Clever lawyers may be able to craft arguments that allow the creators of such systems to avoid liability. Do we need to address this problem? Should we adopt a strict liability approach or a social insurance approach? There are many mooted solutions to this problem, some or all of which could apply to the transport sector.
Transparency/explainability: The machine learning techniques at the heart of modern algorithmic governance systems are notoriously opaque and difficult to explain to end users. This could be a major problem in transport if those systems deny or impede people’s access to transport (and thereby affect their right to freedom of movement) or otherwise interfere with their commuting behaviour in a way that affects their rights or legal position. Some such interferences might be justified/legitimate, but to prove this they will need to be transparent and explainable to those affected. There are various proposals out there to address this problem, some rely on technical solutions to the interpretability problem in machine learning, others on more robust legal regulations that insist upon greater transparency and explainability (some people also argue that the transparency/explainability problem is overstated since human regulatory systems are often opaque and unexplainable).
Fairness/Bias: If the system does affect someone’s access to transport, does it do so in a ‘fair’ or ‘equal’ manner? There are concerns that algorithmic governance systems do little more than reinforce existing stereotypes and biases and so fail to be fair. But what ‘fairness’ actually means, could vary depending on who you ask. Some people think fairness means correcting for historical injustices in access to transport (which seems legitimate since some transport systems have been designed to deliberately exclude or include certain groups of people based on race or social class — Robert Moses’s design of the Long Island parkways being the most well-known example). But others think it means not using protected characteristics (race, gender etc.) in determining how a system works. For those who are interested, I had a long podcast discussion with Reuben Binns about what fairness means or could be taken to mean in such debates. We don’t offer any definitive conclusions, but we at least explore the range of possibilities.
Welfare/Wellbeing: How does the system impact on the wellbeing of those who use the transport system (where ‘wellbeing’ is defined in such a way that excludes the other concerns mentioned above)? Obviously, the hope is that it makes things better, but even if it does there are downstream effects of algorithmic governance systems that need to be factored in. Perhaps the main one in transport is whether the systems ultimate displace lots of human workers from employment in the transport sector. Will these workers be compensated in any way? Should people who make use of these systems actually help to retrain the displaced workers? What about the effects of transport automation? Will it make people lazier and less vigilant when they drive? Will it undermine their moral agency and accentuate their moral patiency (as I have argued before)?
There may well be other impacts that need to be considered, but I think these six, at a minimum, should shape how we think about the regulation of (and by) algorithmic governance systems in transport. It may be that we need to conduct an ‘algorithmic impact assessment’ prior to to the introduction of such a system, as the members of the AI Now institute have been arguing, and as the State of New York seem to accept.
3. Conclusion and Key Take Aways
I won’t conclude by summarising everything I have said to this point. Instead, I’ll conclude with some of my own key takeaways from the conference. These takeaways all connect back to the framework outlined above, and in some sense serve as additional ‘thinking’ principles that can be applied when using that framework. There are really only two of them that stand out in my memory.
First, avoid the compliance trap. I’ve effectively said this already but it bears repeating. I think there is a danger of being too rigid in thinking about the relationship between algorithmic governance systems and the broader regulatory system. In particular, there is a danger of thinking that the algorithmic governance system must always comply with or fit into the pre-existing regulatory system — that all regulatory gaps must be plugged. That may be appropriate on some occasions but not all. There is no guarantee that the pre-existing regulatory system is optimal, and we must be willing to entertain the new modalities or styles of regulation that are made possible by the algorithmic governance system. Indeed, the possibilities afforded to us by the technology might be used to reevaluate or reconstruct the pre-existing regulatory system. Several examples of this came up at the conference. One that stuck with me was a system for the smart allocation and redesignation of public parking spaces that is used in Amsterdam. Instead of using fixed signposts to indicate the times when a parking space could be used, they use a hologram that projects the relevant information directly onto the space and that can be reprogrammed or readjusted on a dynamic basis. It’s a simple example, but illustrates the point because if the pre-existing regulatory system was adopted too rigidly or if didn’t allow for this possibility, the advantage of a flexible, dynamically updated parking allocation system would be lost.
Second, benefits often come with hidden or underappreciated costs. I’m not someone who thinks that technology is perfectly value neutral, but I do think that most technologies can be put to good or bad use. This dual-functionality is important to bear in mind when trying to get the most out of a new technology. In particular, it is important to bear in mind that a technology that has positive consequences along one dimension of value may have negative consequences along others. If we become too fixated on one dimension of value we might lose sight of this. To give an example, many people are deeply concerned about the Chinese ‘social credit system’, which does a number of things, including surveilling and assigning people points based on their compliance with certain regulations, and then denying them access to transport if they accrue number of negative points. It seems like a clearly dystopian use of algorithmic governance in transport. But suppose you didn’t want to deny people access to transport but, instead, wanted to use an algorithmic governance system to grant historically disadvantaged groups preferential access to certain kinds transport (in the interests of ensuring their right to freedom of movement). That sounds like a wonderfully progressive use of technology, right? Maybe, but note that to do this effectively you would probably have to introduce something very similar to the Chinese social credit system, namely a preferential scoring system that monitored and collected data about people to ensure that it could discriminate in their favour. This could lead to more monitoring and surveillance of disadvantaged populations, which could been seen as a cost of introducing the seemingly beneficial system, and could introduce more risk into the system since it the data collected could be used for less progressive and welcome purposes.
So even though we should avoid the compliance trap, and be open to the use of algorithmic governance to improve the way in which transport systems operate, we must not also lose sight of the hidden costs of these systems. We need to broaden our thinking and consider the full sweep of potential impacts, both positive and negative.